
前回

からの続き。
今回から、クラスタリングのプログラム例(下記)の解説に入る。
実装例
# モジュールのインポート
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
import sklearn
from sklearn.cluster import KMeans
# データセットのインポート
file=pd.read_csv('k-means.csv')
# データの割り振り
X=file.iloc[:,0:2]
# 学習実行
# インスタンスの作成
model = KMeans(n_clusters=4,
init='k-means++',
n_init=5,
max_iter=10,
random_state=0)
# モデルの作成
model.fit(X)
# データからの予測値
pred = model.predict(X)
# データセットおよび領域の図示開始
plt.figure(figsize=(4,4))
# カテゴリー領域の図示
x_min = X.iloc[:, 0].min() - 0.5 # 格子点のx座標最小値
x_max = X.iloc[:, 0].max() + 0.5 # 格子点のx座標最大値
y_min = X.iloc[:, 1].min() - 0.5 # 格子点のy座標最小値
y_max = X.iloc[:, 1].max() + 0.5 # 格子点のy座標最大値
h = 0.02 # 格子点生成のステップ数
xx, yy = np.meshgrid(np.arange(x_min, x_max, h), np.arange(y_min, y_max, h)) # 格子点生成
Z = model.predict(np.c_[xx.ravel(), yy.ravel()]) # 格子点全点の予測値算出
Z = Z.reshape(xx.shape) # 予測値の配列の形状をxx(yy)の形状に変更
plt.pcolormesh(xx, yy, Z, cmap=plt.cm.Paired) # 領域を図示
# データおよびセントロイドの図示
plt.scatter(X.iloc[:, 0], X.iloc[:, 1], c=pred , edgecolors='k', cmap=plt.cm.Paired , label='Datas')
plt.scatter(model.cluster_centers_[:,0], model.cluster_centers_[:,1],edgecolors='k', marker="*", label="Centroids", s=300, linewidth=1, color='yellow')
# 軸ラベルおよび凡例の表示
plt.xlabel('x')
plt.ylabel('y')
plt.legend(bbox_to_anchor=(1.05, 1), loc='upper left', borderaxespad=0, fontsize=14)
#図示
plt.show()出力例
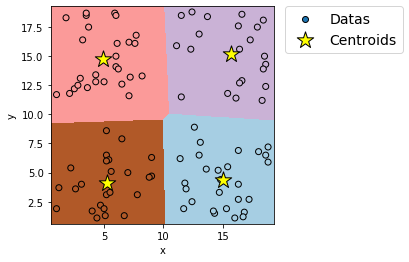
実際にプログラムを実行したい場合は、下記ボタンよりcsvファイル「k-means.csv」をダウンロードしてプログラムの保存先に保存すること。
コード詳説
全てのコードの解説はせず、k-means法に関わる部分に重点を置くことにする。
セントロイドの描画を除く、図の描画に関するコードについては下記を参照。
# データセットのインポート
file=pd.read_csv('k-means.csv')⇒「k-means.csv」というcsvファイルをプログラム内に読み込み、それを変数「file」に格納するためのコード。
今回の例では、「k-means.csv」は下記のように、x-y座標上の点のデータを集めたものになっている。
分類学習では、さらにその横にカテゴリーを示す数値が与えられていたが、教師なし学習のクラスタリングではそれが与えられていない。
| 3.4 | 0.7 |
| 1.8 | 8.4 |
| 3.1 | 0.2 |
| ・ ・ ・ | ・ ・ ・ |
# インスタンスの作成
model = KMeans(n_clusters=4,
init='k-means++',
n_init=5,
max_iter=10,
random_state=0)⇒「KMeans」というクラスを、「model」という名前のインスタンスに作り変えるコード。
インスタンス作成時に引数をいくつか指定することができる。
「n_clusters」で作成するクラスタの数を指定する。
「init」は初期(学習前)のセントロイドの選び方を指定し、「k-means++」では各セントロイドが互いになるべく離れるように選択する。
「n_init」はセントロイドを初期化する回数(「init」で指定した方法で初期のセントロイドを決める回数)を決める。
「max_iter」は「init」でセントロイドを決めてから、セントロイドを重心に移動させる回数の最大値を決める。
# モデルの作成
model.fit(X)
# データからの予測値
pred = model.predict(X)⇒k-means法を実行(学習)するコードと、学習で得られたモデルから予測値を算出するコード。
教師なし学習のため、目的変数や結果量に該当する引数は不要である。
plt.scatter(model.cluster_centers_[:,0], model.cluster_centers_[:,1],edgecolors='k', marker="*", label="Centroids", s=300, linewidth=1, color='yellow')⇒セントロイドを描画するためのコード。
「(インスタンス名).cluster_centers_」はセントロイドの座標を呼び出すコードである。
次回予告
クラスタリングのプログラム例の解説はここで閉じるが、最後に1つおまけ。
クラスタリングでは学習前にクラスタの数を指定しなければならないが、クラスタの数を適当に決めてしまうと適切な学習が実行できない場合がある。
そこで次回、学習に適したクラスタの数を提示し得る手法である「エルボー法」を紹介してクラスタリングの記事を一旦締めることにする。
END

コメント