
前回

にて多項分類問題に対する手法である決定木を見てきた。
今回も多項分類問題を解くための代表的な手法であるk近傍法を扱う。
仕組み
分類したいデータの周囲にあるデータのカテゴリーを調べたとき、そのカテゴリーの中で最も多いデータ数を持つカテゴリーに分類していくのがk近傍法(k-NN)だ。
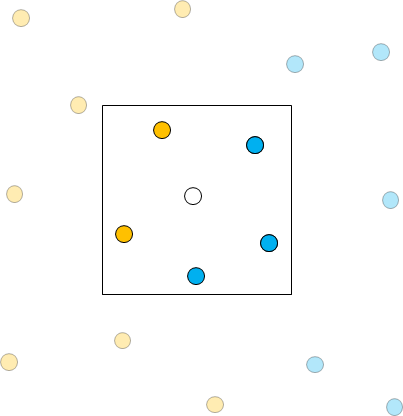
例えば下図の場合、中心の白丸を分類したいデータとすると、周囲に赤丸が9個、青丸が8個あるため、白丸は赤丸に分類される。

ここで注意しなければならないのが、カテゴリーを決める際に参照するデータ数だ。
上の図では赤丸の数が多いが、参照するデータ数を変えると数が逆転することが起こりうる。
ちょうど下図のように、参照するデータ数の取り方によっては青丸の方が数が多くなる。
また、参照するデータ数の取り方によってカテゴリー間の境界の引かれ方も違ってくる。
参照するデータ数が少ない場合、イレギュラーなデータに対応して境界線が急激な変化を見せることがある。
逆に参照するデータ数が多い場合は、境界の引き方が大雑把になって正しい予測ができなくなる場合がある。
実装例
実装例
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
from matplotlib.colors import ListedColormap
import sklearn
from sklearn.neighbors import KNeighborsClassifier
from sklearn import metrics
# データセットのインポート
file=pd.read_csv('tree.csv')
# データの割り振り
X=file.iloc[:,0:2]
Y=file.iloc[:,2]
# データセットを学習データ(8割)とテストデータ(2割)に分割(random_stateは0)
X_train, X_test, Y_train, Y_test = sklearn.model_selection.train_test_split(X, Y, test_size=0.2, random_state=0)
# 分割の確認
print('分割の確認:',X_train.shape, X_test.shape, Y_train.shape, Y_test.shape)
# 学習実行
# インスタンスの作成
model = KNeighborsClassifier(n_neighbors = 5)
# モデルの作成
model.fit(X_train, Y_train)
# 学習データからの予測値
pred_train = model.predict(X_train)
# テストデータからの予測値
pred_test = model.predict(X_test)
# 学習データを用いた分類モデルの評価
print('正解率(学習データ) = ', metrics.accuracy_score(Y_train, pred_train))
# テストデータを用いた分類モデルの評価
print('正解率(テストデータ) = ', metrics.accuracy_score(Y_test, pred_test))
# データセットの図示
plt.figure(figsize=(4,4))
plt.scatter(file.iloc[:,0], file.iloc[:,1], c=file.iloc[:,2], cmap=ListedColormap(['#FF0000', '#0000FF','#00FF00','#808080']))
plt.show()出力例
分割の確認: (80, 2) (20, 2) (80,) (20,)
正解率(学習データ) = 1.0
正解率(テストデータ) = 1.0
実際にプログラムを実行したい場合は、下記ボタンよりcsvファイル「tree.csv」をダウンロードしてプログラムの保存先に保存すること。
詳説
ほとんど前回の決定木のプログラムと同じで、異なるのは下記の2文しかない。
from sklearn.neighbors import KNeighborsClassifier⇒k近傍法のクラスである「KNeighborsClassifier」をインポートするためのコード。
model = KNeighborsClassifier(n_neighbors = 5)⇒クラス「KNeighborsClassifier」を、「model」という名前のインスタンスに作り変えるコード。
引数「n_neighbors」は分類時に参照するデータの数を指定する。
終わりに
番外編も含めてかなり長いこと扱ってきた分類問題も、ここで一区切りつけることにする。
次は、学習用データを用いない教師なし学習を扱っていく予定だ。
参考文献
私が受講した通信講座。
機械学習とはなんぞやという体系的な話からPython操作の基礎、各アルゴリズムの理論、プログラムの実装例まで取り上げ、短期間で最低限の実用レベルまで学ぶことができるようになっている。
最低限の知識で全体を俯瞰しながら実装レベルまで学びたかった私にとって、最適な「足掛かり」となる講座だった。
END
コメント