
前回

にて、scikit-learnを使って決定木をJupyter Notebook上に直接描画する方法を解説した。
今回は「dtreeviz」というパッケージ(モジュール)を使って、より視覚に訴える決定木の図をJupyter Notebook上に直接描画する方法を示す。
先に準備として、決定木を描画するコードを書く前のプログラムを示しておく。
# モジュールのインポート
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
from matplotlib.colors import ListedColormap
import sklearn
from sklearn.tree import DecisionTreeClassifier
from sklearn import metrics
# データセットのインポート
file=pd.read_csv('tree.csv')
# データの割り振り
X=file.iloc[:,0:2]
Y=file.iloc[:,2]
# データセットを学習データ(8割)とテストデータ(2割)に分割(random_stateは0)
X_train, X_test, Y_train, Y_test = sklearn.model_selection.train_test_split(X, Y, test_size=0.2, random_state=0)
# 分割の確認
print('分割の確認:',X_train.shape, X_test.shape, Y_train.shape, Y_test.shape)
# 学習実行
# インスタンスの作成
model = DecisionTreeClassifier(max_depth=2)
# モデルの作成
model.fit(X_train, Y_train)
# 学習データからの予測値
pred_train = model.predict(X_train)
# テストデータからの予測値
pred_test = model.predict(X_test)
# 学習データを用いた分類モデルの評価
print('正解率(学習データ) = ', metrics.accuracy_score(Y_train, pred_train))
# テストデータを用いた分類モデルの評価
print('正解率(テストデータ) = ', metrics.accuracy_score(Y_test, pred_test))
# データセットの図示
plt.figure(figsize=(4,4))
plt.scatter(file.iloc[:,0], file.iloc[:,1], c=file.iloc[:,2], cmap=ListedColormap(['#FF0000', '#0000FF','#00FF00','#808080']))
plt.show()
dtreevizのインストールは下記を参考に、pipインストールで実施すること。
また、実際にプログラムを実行したい場合は、下記ボタンよりcsvファイル「tree.csv」をダウンロードしてプログラムの保存先に保存すること。
方法④:dtreevizを使ってJupyter Notebook上に直接描画
上記プログラムに追加するコードは下記である。
# dtreevizで描画
from dtreeviz.trees import dtreeviz
test_feature = ['x', 'y']
test_class = ['0','1','2','3']
dtreeviz(
model.fit(X_train, Y_train), #学習で得られたモデルのコード。
X_train, #説明変数の学習データセット
Y_train, #目的変数の学習データセット
target_name = 'Class', #目的変数の属名
feature_names = test_feature, #説明変数(特徴量)の名前を指定するコード。
class_names = test_class #目的変数(カテゴリー)の名前を指定するコード。
) コード追加後にプログラムを実行し、下のような図がJupyter Notebook上で表示されれば成功である。
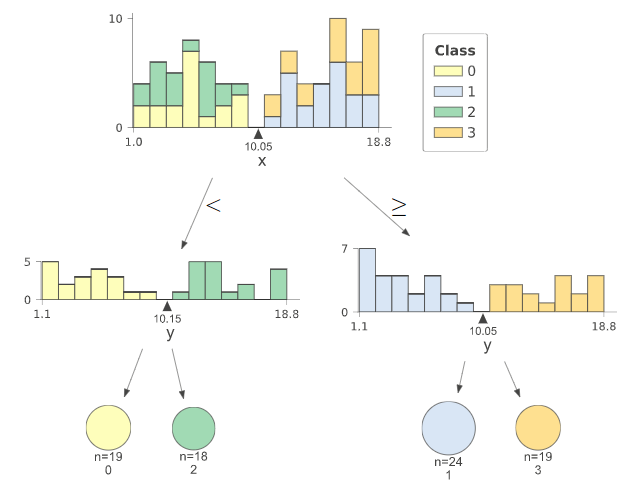
今までの決定木の図とは異なり、棒グラフ等を活用して分岐条件を一目で把握しやすくなっている。
1つ注意点として、描かれる図の形式がsvgであり、Jupyter Notebook上から直接画像を保存できない点が挙げられる。
svgからpngへ変換する方法もあるにはあるが、個人的には面倒に感じたためここにその方法は示さない。
私はというと、スクリーンショットで画像を保存するという全くひねりがない方法を採用している。
ここで、追加したコードを詳しく見ていく。
from dtreeviz.trees import dtreeviz⇒「dtreeviz」をインポートするためのコード。
test_feature = ['x', 'y']
test_class = ['0','1','2','3']⇒説明変数(特徴量)の名前と目的変数(カテゴリー)の名前をそれぞれ、「test_feature」と「test_class」に格納するためのコード。
dtreeviz(
model.fit(X_train, Y_train), #学習で得られたモデルのコード。
X_train, #説明変数の学習データセット
Y_train, #目的変数の学習データセット
target_name = 'Class', #目的変数の属名
feature_names = test_feature, #説明変数(特徴量)の名前を指定するコード。
class_names = test_class #目的変数(カテゴリー)の名前を指定するコード。
) ⇒決定木の画像を描画し、Jupyter Notebook上に表示するためのコード。
各引数についてはコード内のコメント部分を参照。
終わりに
4回に渡って、決定木の図を描画する方法を見てきた。
すべてを試す必要はもちろんなく、自分が気に入った方法を採用してくれれば問題ない。
できればdtreevizで出力したsvg画像を、Jupyter Notebook上でpngに変換して表示する方法を見つけたかったのだが、今のところはなさそうだ。
もし上記の方法を見つけたら、本記事に追記する予定である。
END

コメント