
前回

にて分類問題に対する手法の1つである線形SVMを見てきた。
今まではロジスティック回帰を含め、線形分離可能な分類問題に対する手法しか扱ってこなかったが、今回から線形分離が不可能な分類や、2つ以上のカテゴリーに分類に対応する手法を紹介していく。
今回は線形分離不可能な2項分類に有効な非線形SVMについて。
仕組み
難しいので略。
いずれちゃんとした記事を書きたい。
実装例
実装例
# モジュールのインポート
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
from matplotlib.colors import ListedColormap
import sklearn
from sklearn.svm import SVC
from sklearn import metrics
# データセットのインポート
file=pd.read_csv('NSVM.csv',header=None)
# データの割り振り
X=file.iloc[:,0:2]
Y=file.iloc[:,2]
# データセットを学習データ(8割)とテストデータ(2割)に分割(random_stateは0)
X_train, X_test, Y_train, Y_test = sklearn.model_selection.train_test_split(X, Y, test_size=0.2, random_state=0)
# 分割の確認
print('分割の確認:',X_train.shape, X_test.shape, Y_train.shape, Y_test.shape)
# 学習実行
# インスタンスの作成
model=SVC()
# モデルの作成
model.fit(X_train,Y_train)
# 学習データからの予測値
pred_train = model.predict(X_train)
# テストデータからの予測値
pred_test = model.predict(X_test)
# 学習データを用いた分類モデルの評価
print('正解率(学習データ) = ', metrics.accuracy_score(Y_train, pred_train))
print('適合率(学習データ) = ', metrics.precision_score(Y_train, pred_train))
print('再現率(学習データ) = ', metrics.recall_score(Y_train, pred_train))
print('F値(学習データ) = ', metrics.f1_score(Y_train, pred_train))
# テストデータを用いた分類モデルの評価
print('正解率(テストデータ) = ', metrics.accuracy_score(Y_test, pred_test))
print('適合率(テストデータ) = ', metrics.precision_score(Y_test, pred_test))
print('再現率(テストデータ) = ', metrics.recall_score(Y_test, pred_test))
print('F値(テストデータ) = ', metrics.f1_score(Y_test, pred_test))
# データセットおよび直線の図示
plt.figure(figsize=(4,4))
plt.scatter(file.iloc[:,0], file.iloc[:,1],c=file.iloc[:,2], cmap=ListedColormap(['#FF0000', '#0000FF']))
plt.show()出力例
分割の確認: (80, 2) (20, 2) (80,) (20,)
正解率(学習データ) = 0.975
適合率(学習データ) = 1.0
再現率(学習データ) = 0.9230769230769231
F値(学習データ) = 0.9600000000000001
正解率(テストデータ) = 1.0
適合率(テストデータ) = 1.0
再現率(テストデータ) = 1.0
F値(テストデータ) = 1.0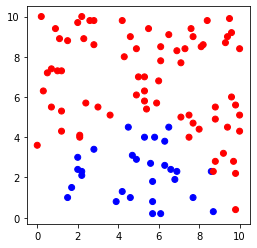
実際にプログラムを実行したい場合は、下記ボタンよりcsvファイル「NSVM.csv」をダウンロードしてプログラムの保存先に保存すること。
詳説
線形SVMの実装例
と比較すると、直線の係数と切片を求めるコードと、直線を描画するコードがなくなり、3つのコードが下記の新しいものになっている。
from sklearn.svm import SVC⇒SVMモデルのクラスである「SVC」をインポートするためのコード。
file=pd.read_csv('NSVM.csv',header=None)⇒「NSVM.csv」というcsvファイルを、ヘッダーなしでプログラム内に読み込み、それを変数「file」に格納するためのコード。
データ構造はロジスティック回帰と線形SVMで使用したデータセットと同じであり、x-y座標上の点に対して「0」または「1」の値を割り振ったデータが100個集まったものになっている。
model=SVC()⇒クラス「SVC」を、「model」という名前のインスタンスに作り変えるコード。
次回予告
次回は複数の条件から分岐を繰り返して分類する「決定木」を扱う。
参考文献
私が受講した通信講座。
機械学習とはなんぞやという体系的な話からPython操作の基礎、各アルゴリズムの理論、プログラムの実装例まで取り上げ、短期間で最低限の実用レベルまで学ぶことができるようになっている。
最低限の知識で全体を俯瞰しながら実装レベルまで学びたかった私にとって、最適な「足掛かり」となる講座だった。
END

コメント