
前回

の続き。
今回はロジスティック回帰の実装例解説の最終回。
といっても、実装例の本筋からは外れた、グラフの描画するコードの解説である。
実装例
# モジュールのインポート
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
from matplotlib.colors import ListedColormap
import sklearn
from sklearn.linear_model import LogisticRegression
from sklearn import metrics
# データセットのインポート
file=pd.read_csv('logistic.csv',header=None)
# データの割り振り
X=file.iloc[:,0:2]
Y=file.iloc[:,2]
# データセットを学習データ(8割)とテストデータ(2割)に分割(random_stateは0)
X_train, X_test, Y_train, Y_test = sklearn.model_selection.train_test_split(X, Y, test_size=0.2, random_state=0)
# 分割の確認
print('分割の確認:',X_train.shape, X_test.shape, Y_train.shape, Y_test.shape)
# 学習実行
# インスタンスの作成
model=LogisticRegression()
# モデルの作成
model.fit(X_train,Y_train)
# 直線の確認
# 切片
print('切片の値 = ', model.intercept_)
# 係数
print('係数の値 = ', model.coef_)
# 学習データからの予測値
pred_train = model.predict(X_train)
# テストデータからの予測値
pred_test = model.predict(X_test)
# 学習データを用いた分類モデルの評価
print('正解率(学習データ) = ', metrics.accuracy_score(Y_train, pred_train))
print('適合率(学習データ) = ', metrics.precision_score(Y_train, pred_train))
print('再現率(学習データ) = ', metrics.recall_score(Y_train, pred_train))
print('F値(学習データ) = ', metrics.f1_score(Y_train, pred_train))
# テストデータを用いた分類モデルの評価
print('正解率(テストデータ) = ', metrics.accuracy_score(Y_test, pred_test))
print('適合率(テストデータ) = ', metrics.precision_score(Y_test, pred_test))
print('再現率(テストデータ) = ', metrics.recall_score(Y_test, pred_test))
print('F値(テストデータ) = ', metrics.f1_score(Y_test, pred_test))
# データセットおよび直線の図示
plt.figure(figsize=(4,4))
plt.scatter(file.iloc[:,0], file.iloc[:,1],c=file.iloc[:,2], cmap=ListedColormap(['#FF0000', '#0000FF']))
plt.plot(file.iloc[:,0], -file.iloc[:,0]*model.coef_[0,0]/model.coef_[0,1]-model.intercept_[0]/model.coef_[0,1])
plt.show()出力例
分割の確認: (160, 2) (40, 2) (160,) (40,)
切片の値 = [-9.71024304]
係数の値 = [[0.04871103 1.89741032]]
正解率(学習データ) = 0.91875
適合率(学習データ) = 0.9195402298850575
再現率(学習データ) = 0.9302325581395349
F値(学習データ) = 0.9248554913294798
正解率(テストデータ) = 0.875
適合率(テストデータ) = 0.8125
再現率(テストデータ) = 0.8666666666666667
F値(テストデータ) = 0.8387096774193549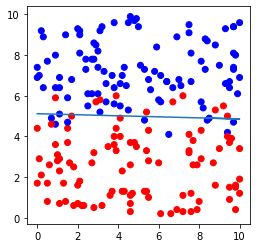
実際にプログラムを実行したい場合は、下記ボタンよりcsvファイル「logistic.csv」をダウンロードしてプログラムの保存先に保存すること。
9. 結果のグラフ描画
プログラムの最後に書かれているのは、グラフ描画のためのコードである。
# データセットおよび直線の図示
plt.figure(figsize=(4,4))
plt.scatter(file.iloc[:,0], file.iloc[:,1],c=file.iloc[:,2], cmap=ListedColormap(['#FF0000', '#0000FF']))
plt.plot(file.iloc[:,0], -file.iloc[:,0]*model.coef_[0,0]/model.coef_[0,1]-model.intercept_[0]/model.coef_[0,1])
plt.show()
plt.figure(figsize=(横のサイズ,縦のサイズ))
は図を描く領域を用意するためのコードである(イメージは絵を描く画用紙)。
画像ファイルとして保存できるのはこの「plt.figure」単位である。
1つの領域に複数グラフを描画することもできるし、複数の領域を用意して1つずつグラフを描画することもできる。
サイズ指定の単位はインチで、デフォルトは(8,6)である。
plt.scatter(x,y,引数)
は散布図を描画するコードである。
「x」にx軸のデータ群、「y」にy軸のデータ群を入力する。
引数にはいくつかあるが、今回用いているのは「c」と「cmap」である。
「c」は色を、「cmap」はカラーマップを指定する。
plt.plot(x,y)
はグラフを描画するコードである。
「x」にx軸のデータ群、「y」にy軸のデータ群を入力する。
以上を踏まえて、実装例のコードを詳しく見ていくと次のようになる。
plt.figure(figsize=(4,4))⇒図を描画する領域を4インチ×4インチのサイズで準備するためのコード。
plt.scatter(file.iloc[:,0], file.iloc[:,1],c=file.iloc[:,2], cmap=ListedColormap(['#FF0000', '#0000FF']))⇒データ群「file.iloc[:,0]」をx、データ群「file.iloc[:,1]」をyとして散布図を描画するコード。
色は「file.iloc[:,2]」、すなわち0か1の2つしかとらないようにし、カラーマップで具体的な色を指定する。
「ListedColormap」は不連続なカラーマップであり、「#FF0000」と「#0000FF」はそれぞれ赤色と青色を示すカラーコードである。
以上のコードを実行すると、下記の図が描画される。
次回予告
ロジスティック回帰の実装例解説は今回で終了だが、あと何回か使って分類問題を解くためのいくつかの手法を紹介しようと思う。
最初はロジスティック回帰と同様、線形分離可能な分類問題に有効な「線形SVM」から見ていく。
参考文献
私が受講した通信講座。
機械学習とはなんぞやという体系的な話からPython操作の基礎、各アルゴリズムの理論、プログラムの実装例まで取り上げ、短期間で最低限の実用レベルまで学ぶことができるようになっている。
最低限の知識で全体を俯瞰しながら実装レベルまで学びたかった私にとって、最適な「足掛かり」となる講座だった。
END
※追記
「線形SVM」の記事執筆。

コメント