

にて、分類アルゴリズムの1つである「決定木」を扱った。
ここで決定木のイメージ図として、分岐を繰り返しながら分類を実行する図(下図)を示したが、実はPython上でこの図を描画することが可能だ。
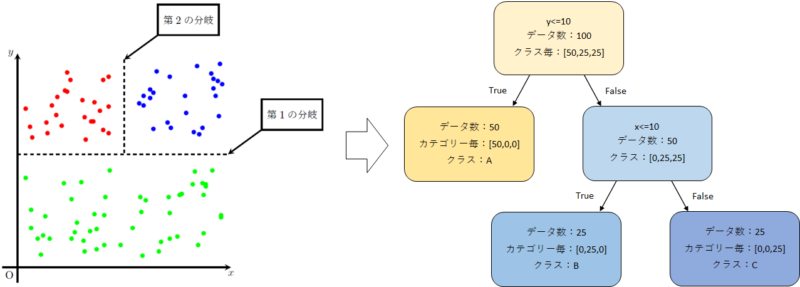
今回は4回に渡って4通りの決定木描写方法について解説する。
まずは最もメジャーな手法であるGraphvizを用いた方法から。
「Graphviz」の概要とインストール方法は下記を参照。
決定木描画前のプログラム
最初に準備として、決定木を描画するコードを書く前のプログラムを示しておく。
# モジュールのインポート
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
from matplotlib.colors import ListedColormap
import sklearn
from sklearn.tree import DecisionTreeClassifier
from sklearn import metrics
# データセットのインポート
file=pd.read_csv('tree.csv')
# データの割り振り
X=file.iloc[:,0:2]
Y=file.iloc[:,2]
# データセットを学習データ(8割)とテストデータ(2割)に分割(random_stateは0)
X_train, X_test, Y_train, Y_test = sklearn.model_selection.train_test_split(X, Y, test_size=0.2, random_state=0)
# 分割の確認
print('分割の確認:',X_train.shape, X_test.shape, Y_train.shape, Y_test.shape)
# 学習実行
# インスタンスの作成
model = DecisionTreeClassifier(max_depth=2)
# モデルの作成
model.fit(X_train, Y_train)
# 学習データからの予測値
pred_train = model.predict(X_train)
# テストデータからの予測値
pred_test = model.predict(X_test)
# 学習データを用いた分類モデルの評価
print('正解率(学習データ) = ', metrics.accuracy_score(Y_train, pred_train))
# テストデータを用いた分類モデルの評価
print('正解率(テストデータ) = ', metrics.accuracy_score(Y_test, pred_test))
# データセットの図示
plt.figure(figsize=(4,4))
plt.scatter(file.iloc[:,0], file.iloc[:,1], c=file.iloc[:,2], cmap=ListedColormap(['#FF0000', '#0000FF','#00FF00','#808080']))
plt.show()このプログラムは下記で示した実装例と全く同じである。
このプログラムに追加のコードを記述するだけで、決定木を描画できるプログラムに仕上げる。
また、実際にプログラムを実行したい場合は、下記ボタンよりcsvファイル「tree.csv」をダウンロードしてプログラムの保存先に保存すること。
方法①:dotファイルを保存してからpng画像に変換
この手法は、決定木描画の方法の中で(おそらく)最もメジャーなものだ。
まずプログラムに下記コードを追加した上で、プログラムを実行する。
# graphvizで描画(dotファイルをエクスポート)
from sklearn.tree import export_graphviz
import os
test_feature = ['x', 'y']
test_class = ['0','1','2','3']
export_graphviz(
model.fit(X_train, Y_train), #学習で得られたモデルのコード。
out_file = os.path.join("dtcexp.dot"), #プログラムの保存先にdotファイルを保存させるためのコード。
filled = True, #ノードに色をつけるためのコード。
rounded = True, #ノードの角を丸くするコード。
feature_names = test_feature, #説明変数(特徴量)の名前を指定するコード。
class_names = test_class #目的変数(カテゴリー)の名前を指定するコード。
)プログラム実行後、プログラムが保存されているフォルダ内にdotファイルが保存されていることを確認する。
続いてコマンドプロンプトを開き、下記コードを入力して実行する。
dot -Tpng (dotファイルまでのファイルパス) -o (変換後のpngファイルまでのファイルパス)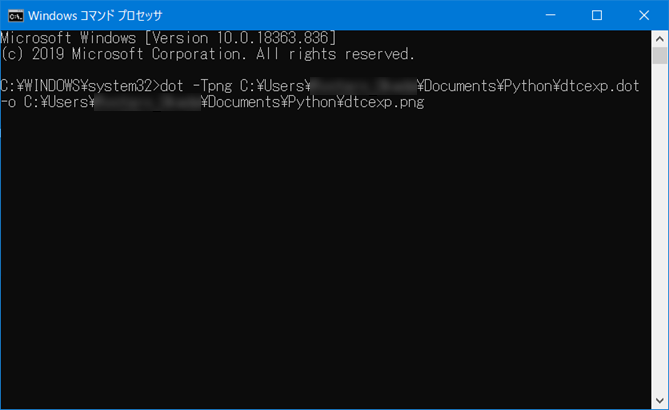
pngファイルの保存先に指定したフォルダにpngファイルが保存されており、下のような決定木の図になっていればOK。
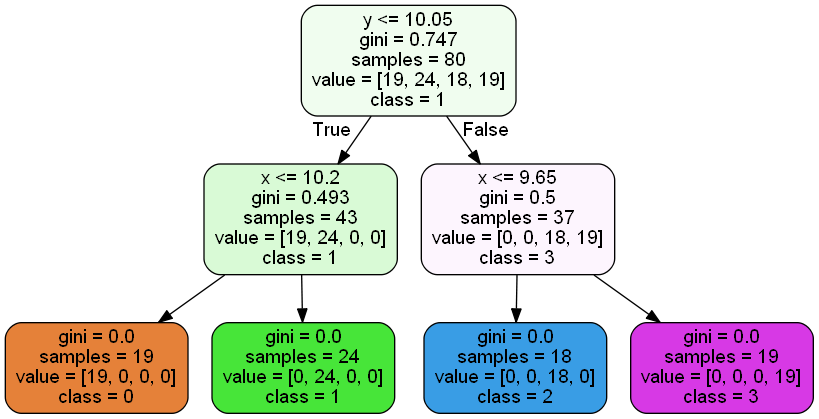
ここで、追加したコードを詳しく見ていく。
from sklearn.tree import export_graphviz
import os⇒決定木描画に必要なモジュールをインポートするためのコード。
test_feature = ['x', 'y']
test_class = ['0','1','2','3']⇒説明変数(特徴量)の名前と目的変数(カテゴリー)の名前をそれぞれ、「test_feature」と「test_class」に格納するためのコード。
今回は、xとyという2つの値の組み合わせから成るデータが、「0」から「3」の値によってナンバリングされている。
xとyの2つの値から、データを「0」から「3」のどれかに分類するプログラムだからxとyが説明変数、「0」から「3」が目的変数になる。
export_graphviz(
model.fit(X_train, Y_train), #学習で得られたモデルのコード。
out_file = os.path.join("dtcexp.dot"), #プログラムの保存先にdotファイルを保存させるためのコード。
filled = True, #ノードに色をつけるためのコード。
rounded = True, #ノードの角を丸くするコード。
feature_names = test_feature, #説明変数(特徴量)の名前を指定するコード。
class_names = test_class #目的変数(カテゴリー)の名前を指定するコード。
)⇒決定木の画像をdot形式で出力、フォルダに保存するためのコード。
各引数についてはコード内のコメント部分を参照。
ノードとは、枝の節目にある、分岐の条件やデータ数が記されている部分を指す。
この方法を最初に見つけ、無事決定木を描画できたわけだが、同時に
一回dotファイルで落としてからcmdでpngにするのは面倒だな。
プログラム内でpngにしてかつJupyter Notebook上で表示できる方法はないか?
とも思った。
実際に調べると、やはり同じように考えている人はいるもので、Jupyter Notebook上で直接決定木を描画、表示する方法をいくつか見つけた。
次回はその中から、今回と同様にGraphvizを使う方法を紹介する。
下記に続く。
コメント