
前回

の続き。
今回は分類学習の実行するコードと、学習の結果得られた直線の係数と切片および予測値を確認するコードを見ていく。
実装例
# モジュールのインポート
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
from matplotlib.colors import ListedColormap
import sklearn
from sklearn.linear_model import LogisticRegression
from sklearn import metrics
# データセットのインポート
file=pd.read_csv('logistic.csv',header=None)
# データの割り振り
X=file.iloc[:,0:2]
Y=file.iloc[:,2]
# データセットを学習データ(8割)とテストデータ(2割)に分割(random_stateは0)
X_train, X_test, Y_train, Y_test = sklearn.model_selection.train_test_split(X, Y, test_size=0.2, random_state=0)
# 分割の確認
print('分割の確認:',X_train.shape, X_test.shape, Y_train.shape, Y_test.shape)
# 学習実行
# インスタンスの作成
model=LogisticRegression()
# モデルの作成
model.fit(X_train,Y_train)
# 直線の確認
# 切片
print('切片の値 = ', model.intercept_)
# 係数
print('係数の値 = ', model.coef_)
# 学習データからの予測値
pred_train = model.predict(X_train)
# テストデータからの予測値
pred_test = model.predict(X_test)
# 学習データを用いた分類モデルの評価
print('正解率(学習データ) = ', metrics.accuracy_score(Y_train, pred_train))
print('適合率(学習データ) = ', metrics.precision_score(Y_train, pred_train))
print('再現率(学習データ) = ', metrics.recall_score(Y_train, pred_train))
print('F値(学習データ) = ', metrics.f1_score(Y_train, pred_train))
# テストデータを用いた分類モデルの評価
print('正解率(テストデータ) = ', metrics.accuracy_score(Y_test, pred_test))
print('適合率(テストデータ) = ', metrics.precision_score(Y_test, pred_test))
print('再現率(テストデータ) = ', metrics.recall_score(Y_test, pred_test))
print('F値(テストデータ) = ', metrics.f1_score(Y_test, pred_test))
# データセットおよび直線の図示
plt.figure(figsize=(4,4))
plt.scatter(file.iloc[:,0], file.iloc[:,1],c=file.iloc[:,2], cmap=ListedColormap(['#FF0000', '#0000FF']))
plt.plot(file.iloc[:,0], -file.iloc[:,0]*model.coef_[0,0]/model.coef_[0,1]-model.intercept_[0]/model.coef_[0,1])
plt.show()出力例
分割の確認: (160, 2) (40, 2) (160,) (40,)
切片の値 = [-9.71024304]
係数の値 = [[0.04871103 1.89741032]]
正解率(学習データ) = 0.91875
適合率(学習データ) = 0.9195402298850575
再現率(学習データ) = 0.9302325581395349
F値(学習データ) = 0.9248554913294798
正解率(テストデータ) = 0.875
適合率(テストデータ) = 0.8125
再現率(テストデータ) = 0.8666666666666667
F値(テストデータ) = 0.8387096774193549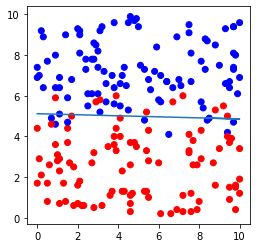
実際にプログラムを実行したい場合は、下記ボタンよりcsvファイル「logistic.csv」をダウンロードしてプログラムの保存先に保存すること。
5. 学習の実行
データの下準備が完了したらいよいよ分類の実行。
# 学習実行
# インスタンスの作成
model=LogisticRegression()
# モデルの作成
model.fit(X_train,Y_train)インスタンスに関しては下記記事を参照。
実装例のコードを詳しく見ていくと次のようになる。
model=LogisticRegression()⇒「LogisticRegression」というクラスを、「model」という名前のインスタンスに作り変えるコード。
model.fit(X_train,Y_train)⇒インスタンス「model」から関数「fit」を呼び出し、X_trainを特徴量、Y_trainを結果量として二項分類を実行するコード。
6. 直線の係数・切片の確認
5にて、データセットを2つのカテゴリーに分類する直線が引けたので、ここでその直線の係数と切片を確認する。
# 直線の確認
# 切片
print('切片の値 = ', model.intercept_)
# 係数
print('係数の値 = ', model.coef_)コード自体は下記記事
にて解説したものと同じコードだが、ロジスティック回帰ではコードの出力値が分類する直線の係数と切片に変わる。
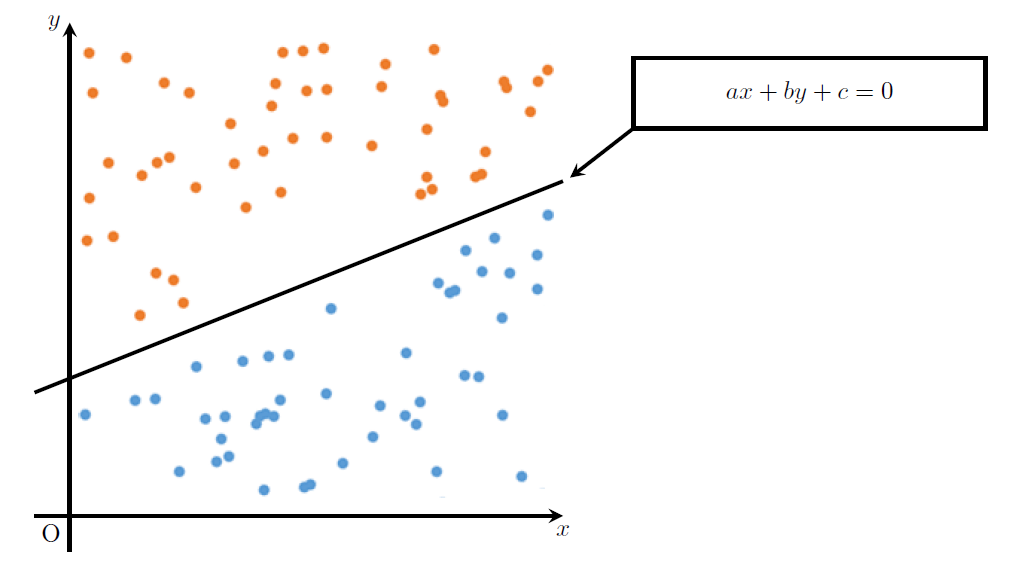
すなわち、下のグラフのように2つのカテゴリーに分類する直線
\begin{align}
ax+by+c=0 \tag{1}\label{chokusen}
\end{align}
の係数\(a,b\)と切片\(c\)を出力させることができる。
実装例のコードを詳しく見ていくと次のようになる。
print('切片の値 = ', model.intercept_)⇒先の学習で求められた直線の切片をprint関数で表示するためのコード。
出力は下記のようになる。
切片の値 = [-9.71024304]
print('係数の値 = ', model.coef_)⇒先の学習で求められた直線の係数をprint関数で表示するためのコード。
出力は下記のようになる。
係数の値 = [[0.04871103 1.89741032]]左の数値が(\ref{chokusen})の\(a\)、右の数値が\(b\)である。
7. 予測値の導入
学習を実行してモデルが生成されたらモデル評価を実施するが、その前に下準備として予測値を導入する。
# 学習データからの予測値
pred_train = model.predict(X_train)
# テストデータからの予測値
pred_test = model.predict(X_test)コード自体は下記記事
にて解説したものと同じコードだが、今回は前回生成した分類モデルから各データを分類して「0」または「1」を割り当てている。
実装例のコードを詳しく見ていくと次のようになる。
pred_train = model.predict(X_train)
pred_test = model.predict(X_test)⇒変数pred_trainおよびpred_testに、学習データおよびテストデータからの予測値を代入するコード。
次回予告
次回は、実行の結果生成されたモデルを評価するコードの解説に入る。
END
※追記
モデルを評価するコードについて。
コメント