
本記事は、私がG検定の勉強をした際にまとめた用語、手法等の解説をまとめたノートである。
実際に受検した際も本記事を利用し、合格の一助となった。
完全に自分用に作成したものだが、せっかくなので公開する。
勉強に際し使用した書籍
各用語の横に「(公式、赤本、青本、問題集)」といった記述があるが、これはその用語が掲載されている書籍をメモしたものであり、それぞれ次の書籍に該当する。
公式
↓
赤本
↓
青本
↓
問題集
↓
人工知能(AI)とは(人工知能の定義)
人工知能の定義
人工知能 (公式、赤本、青本、問題集)
言葉自体は、ダートマス会議でジョン・マッカーシーが初めて使用。
「推論、認識、判断など、人間と同じ知的な処理能力を持つ機械(情報処理システム)」
「人工知能は何か?」という定義はない。
人工知能の大まかな分類 (公式、赤本、青本、問題集)
レベル1:シンプルな制御プログラム(制御工学の範疇)
レベル2:古典的な人工知能
レベル3:機械学習を取り入れた人工知能
レベル4:ディープラーニングを取り入れた人工知能
AI効果 (公式、赤本、青本、問題集)
人工知能で新しいことが実現され、その原理が判明すると、「それは単純な自動化であって知能とは無関係だ」と結論付ける人間の心理。
人工知能とロボットの違い (公式、青本)
人工知能はロボットの脳に該当する。
人工知能の歴史
エニアック(ENIAC) (公式、問題集)
世界初の汎用コンピュータ。
人工知能研究のブームと冬の時代 (公式、赤本、問題集)
第1次AIブーム:推論・探索の時代。「トイ・プロブレム(おもちゃの問題)」しか解けない。
第2次AIブーム:知識の時代。エキスパートシステムが作られた。膨大な知識の蓄積が必要。
第3次AIブーム:機械学習・特徴表現学習の時代。現在のブーム。
その他用語
ロジック・セオリスト(公式)
人工知能をめぐる動向
探索・推論
探索木 (公式、赤本、青本、問題集)
幅優先探索
・横方向に場合分けを全て調べる。
・場合分けを全て記憶(記憶量多)。
・解までのステップ数が少ない場合に短時間で終了しやすい。
深さ優先探索
・行き止まりになるまで下へ調べる。
・ハズレなら記憶しない(記憶量少)。
・解までのステップ数が多い場合に短時間で終了しやすい。
コスト (公式、問題集)
ボードゲームの最善手探索において、盤面が自分にとってどれほど有利かを定量的に示す値。
「スコア」とも呼ばれる。
Mini-Max法 (公式、問題集)
下記の2つのルールのもとで、ボードゲームの最善手を探索する方法。
・自分のターン:コストが最大になる手を選ぶ。
・相手のターン:コストが最小になる手を選ぶ。
基本は深さ優先探索で実施され、ゲームの終盤で適用される場合が多い。
この手法の上で、条件に応じて途中で探索を打ち切って探索数を削減する手法にαβ法(公式、問題集)がある。

モンテカルロ法 (公式、問題集)
ボードゲームにおいて、自分の勝敗を許容しつつ、ある手から数多くのシミュレーションをして最善手(最適なスコア)を探索(評価)する手法。
ゲームの序盤と中盤のコストを暫定的に決める際に用いられる。
このように多数のシミュレーションを計算する探索方法はブルートフォース(力任せ)(公式、赤本)と呼ばれる。
ハノイの塔 (公式、問題集)
中央に穴の開いた複数の円盤が3本の杭を移動していくパズル。
プランニング (公式)
ロボットの行動計画を探索を利用して作成する技術。
「自動計画」(問題集)とも呼ばれる。
STRIPS (公式、問題集)
「Stanford Research Institute Problem Solver」の略。
「前提条件」、「行動」、「結果」の3つの組み合わせで自動計画を記述できる言語。
リチャード・ファイクスとニルス・ニルソンが開発。
SHRDLU (公式、問題集)
自動計画を端末画面の中の「積み木の世界」で実現することを目指す研究。
1970年、スタンフォード大学のテリー・ウィノグラードが実施。
その他用語
AlphaGo(公式) ヒューリスティックな知識(公式)
知識表現
人口無能 (公式、赤本、問題集)
チャットボット、おしゃべりロボット。
ELIZA(イライザ) (公式、赤本、青本、問題集)
1964年~1966年にかけてジョセフ・ワイゼンバウムによって開発された会話ロボット。
エキスパートシステム (公式、赤本、青本、問題集)
1980年代に登場。
ある専門分野の知識を取り込み、その分野のエキスパート(専門家)のように振る舞うプログラム。
Mycin (公式、青本、問題集)
伝染性の血液疾患を診断し、抗生物質を推奨するようにデザインされたプログラム。
DENDRAL (公式、問題集)
未知の有機化合物を特定するプログラム。
意味ネットワーク (公式、赤本、青本、問題集)
「概念」をラベルの付いたノードで表し、概念間の関係をラベルの付いたリンク(矢印)で結んだネットワーク。
「is-a」の関係 (公式、青本)
継承関係を表し、矢印が向いている側が上位概念、矢印の始点が下位概念となる。
「part-of」の関係 (公式、青本)
属性を表す。
ナレッジグラフ (問題集)
データベースにある知識を半自動的に落とし込んで構築された意味ネットワーク。
活用例:LOD(Linked Open Data)、チャットボット、専門性の高い分野(金融など)、Mercari
Cycプロジェクト (公式、赤本、青本、問題集)
一般常識を全てコンピュータに取り込もうとするプロジェクト。
1984年から開始され、現在も続いている。
オントロジー (公式、青本、問題集)
一般常識の意味ネットワークの記述方式を決める、汎用的で厳格的なルール。
哲学用語としては、「存在論」を意味する。
情報科学の分野では、「概念化の明示的な仕様」を意味する。
セマンティックウェブなどで使用される概念を定義するための辞書としての役割がある。
ヘビーウェイトオントロジー (公式、青本)
対象世界の知識をどのように記述するか哲学的にしっかり考えて行うもの。
(例)Cycプロジェクト
ライトウェイトオントロジー (公式、青本)
効率を重視し、とにかくコンピュータにデータを読み込ませてできる限り自動的に行うもの。
(例)ワトソン
拡張知能(Augmented Intelligence) (問題集)
IBMによるAIの定義で、あくまで人間を補助するものと捉えている。
IBMが開発した質問応答プログラム「ワトソン(Watson)」(公式、赤本、青本、問題集)に対してつけられたもの。
日本でも「東ロボくん」(公式、赤本、青本、問題集)と呼ばれる同様の質問応答プログラムがある。
その他用語
セマンティック・ウェブ(赤本)、イライザ効果(青本)、形式知(青本)、暗黙知(青本)
人工知能分野の問題
トイ・プロブレム(おもちゃの問題) (公式、赤本)
現実の複雑な問題を、コンピュータが扱えかつ本質を損なわない程度に簡略化したもの。
フレーム問題 (公式、赤本、青本、問題集)
ロボットは問題解決の枠にとらわれて、その枠の外を想像するのが難しい、という問題。
また、人間が自然と行っている「いま解こうとしている問題に関係のあることだけを選び出す」ということが、人工知能にとって非常に難しいという問題。
1969年にジョン・マッカーシーとパトリック・ヘイズによって提唱。
ダニエル・デネットによりその具体的な思考実験が提案された。
チューリングテスト (公式、赤本、青本、問題集)
ある対話式の機械に対して「人間的」か否かを判定するためのテスト。
1950年にイギリスの数学者であるアラン・チューリングが提案。
チューリングテストのコンテストであるローブナーコンテストでは、優秀な機械にはローブナー賞が贈られる。
中国語の部屋 (公式、赤本、問題集)
ジョン・サールが執筆した論文内で発表された思考実験。
中国語が話せない人を、中国語のマニュアルとともに部屋に閉じ込め、部屋に空いた穴から中国語の紙を差し込んで翻訳させても十分な翻訳が得られるため、
この思考実験を根拠に、ジョン・サールはチューリングテストの結果は何の指標にもならないと主張した。
強いAIと弱いAI
強いAI (公式、赤本、青本、問題集)
人間の思考は情報処理であり、人間の心と同等の心をコンピュータで実現できるという立場。
人間の知的処理を総合的に行えるAI。
「汎用型人工知能」(問題集)とも言う。
(例)ドラえもん、ターミネーターなど。
弱いAI (公式、赤本、青本、問題集)
コンピュータは人間の心を持つ必要はなく、有用な道具であればよいとする立場。
1つのタスクに特化したAI。
現在「AI」と呼ばれて社会に適用されている技術。
「特化型人工知能」(問題集)とも言う。
(例)AlphaGo、AlexNetなど。
シンボルグラウンディング問題(記号接地問題) (公式、赤本、青本、問題集)
「記号とその対象がいかにして結びつくか」という問題。
人間は「シマウマ」という言葉だけ知っていて現物を見たことがなくても、現物を見れば「シマウマ」という単語と現物を結び付けられるが、コンピュータはそれができない。
機械翻訳 (公式、問題集)
●ルールベース機械翻訳(RBMT) (公式、問題集)
各言語の文法を人の手で入力していき、変換していくもの。
人の手では限界があること、言語自体が非常に柔軟であることから使いにくく頓挫。
●統計的機械翻訳(SMT) (公式、問題集)
ある言語とその対訳を学習させてモデルとするもの(機械学習に近い)。
人の手によるルール追加による莫大なコストはかからなくなったが、精度は現実的に運用できるレベルに至らず。
代表手法にNグラム法がある。
●ニューラル機械翻訳(NST) (公式、問題集)
ニューラルネットワークを用いた機械翻訳。
データが溜まるほど翻訳精度が向上する。現在の機械翻訳の主流。
身体性 (公式)
AI が実世界における抽象概念を理解し、知識処理を行う上では、身体性を通じた高レベルの身体知を獲得し、次に身体知を通じて言語の意味理解を促し、抽象概念・知識処理へと至るのではないかということが議論されている。
知識獲得のボトルネック (公式、赤本)
・知識としてのルールの整合性や一貫性を保つのが困難である。
・専門家から体系だった知識を引き出し、システムを構築することが困難である。
・常識などの定義が困難である。
モラベックのパラドックス (赤本)
コンピュータが難解なパズルや数式を容易に解くことができても、実は人間が幼児の頃から無意識に行っている認識や運動を実現することこそが非常に難しいということ。
人間にとって簡単なことほど機械がやるのは難しいと呼ばれる考え。
シンギュラリティ(技術的特異点) (公式、赤本、青本、問題集)
人工知能が人間の知能を超える点。
レイ・カーツワイルが2045年と予測。
人間が自らの知能を超えた人工知能を生み出した場合、その人工知能も同じことが出来るはずで、それが繰り返されると技術的な進化が爆発的に起きるとされている。
機械学習の具体的手法
全体的に赤本がうまくまとまっている。
教師あり学習
教師あり学習 (公式、赤本、青本、問題集)
正解データが未知であるサンプルに対して、その値を予測するモデルを得る。
小脳の働きを模倣した学習法。
回帰問題 (公式、赤本、青本、問題集)
正解データが量的変数(連続値)。
出力層で恒等関数が用いられる。
分類問題 (公式、赤本、青本、問題集)
正解データが質的変数(カテゴリ)。
教師あり学習の主な手法(アルゴリズム)
線形回帰 (公式、赤本、青本、問題集)
●回帰問題
●目的変数の範囲:\(-\infty < y <\infty\)
●説明変数が1つの場合を単回帰モデル、説明変数が2つ以上の場合を重回帰モデルと呼び、各項の係数パラメータを偏回帰係数という。
●(偏)回帰係数から説明変数の重要さについて推察する場合。
⇒正規化などの前処理を行って説明変数のスケールを揃え、(偏)回帰係数の絶対値が大きなものを重要とみなす。
●多重共線性 (問題集)
説明変数同士の相関が高すぎると、単独の影響を分離したり、その効果を評価することが難しくなること。
正則化 (公式、赤本、青本、問題集)
損失関数の値とともに、モデルのパラメータの二乗和を最小になるように学習すること。
学習の際にペナルティとなる項を追加し、汎化誤差を可能なかぎり小さくすることで過学習を防ぐ。
●Lasso回帰 (公式、赤本、青本、問題集)
L1正則化を適用した方法。
正則化パラメータが大きくなるに従い、回帰係数をスパースに(0になるものが多くなるように)推定する効果が強くなる。
●Ridge回帰 (公式、赤本、青本、問題集)
L2正則化を適用した方法。
正則化パラメータが大きくなるに従い、回帰係数を0に近づける効果が強くなる。
●荷重減衰
ディープニューラルネットワーク(DNN)の学習で一般に用いられる正則化の手法の1つ。
誤差関数に重みのL2ノルムを加えることで重みの発散を抑える。
L2ノルムの代わりにL1ノルムを用いるL1正則化は、スパース正則化の一種であり、重要でないパラメータを0に近づける
ロジスティック回帰 (公式、赤本、青本、問題集)
●2値分類問題
●目的変数の範囲:\(y=0,1\)
●モデルの出力にシグモイド関数を用いる(多値分類ではソフトマックス関数)。
サポートベクトルマシン(SVM) (公式、赤本、青本、問題集)
●回帰、分類問題
●マージンの最大化を行う。
●カーネル法 (赤本、青本、問題集)
線形分離可能でないデータを高次元空間に移し、高次元空間内で線形分離する手法。
●カーネルトリック (公式、赤本、青本、問題集)
カーネル法をカーネル関数(公式、赤本、青本)を用いて実施し、計算量の増加を低く抑えるためのテクニック。
●スラック変数
SVMなどのアルゴリズムで、一部の誤分類を寛容にするため使用される変数。
k-近傍法 (赤本、問題集)
●回帰、分類
●与えられた学習データをベクトル空間上にプロットし、未知のデータに対し、そこから距離が近い順に任意のk個を取得し、その多数決でデータが属するクラスを推定する。
●スケールの大きい特徴量に左右されすぎないように適切な前処理が必要。
●k=1のときに最も複雑で入り組んだものになる。
決定木 (公式、赤本、青本、問題集)
●分類、回帰
アンサンブル学習 (公式、赤本、青本、問題集)
性能の低い学習(弱学習器)を組み合わせて、全体の汎化性能をあげた高性能の学習器を作り出す方法。
決定木のアンサンブル学習のモデルでは、それぞれの特徴量による分割回数などを利用して特徴量の重要度(importance)を定義する。
●バギング(bagging) (公式、赤本、青本、問題集)
弱学習器を並列に学習して組合わせる手法。
元データから重複ありでランダムにデータを取得(ブーストラップサンプリング、重複ありランダムサンプリング)し、並列に学習して、多数決で分類結果を出力する。
・ランダムフォレスト (公式、赤本、青本、問題集)
弱学習器として決定木を用いるバギングの一種。
データだけでなく、特徴量もランダムに選び出す。
●ブースティング (公式、赤本、青本、問題集)
弱学習器を順番に(逐次的に)学習させて組み合わせて強くしていく方法。
前の学習器が誤分類したデータを優先的に正しく分類できるように学習していく。
弱学習器の数が多くなりすぎると過学習を起こしてしまう。
・adaboost (公式、青本、問題集)
・勾配ブースティング (赤本、青本、問題集)
損失関数として勾配降下法を使用。
弱学習器に決定木を利用した勾配ブースティング木(GBDT)のライブラリに「catboost」、「lightgbm」、「xgboost」がある。
●スタッキング (問題集)
あるモデルによる予測値を新たなモデルの特徴量(メタ特徴量)とする手法。
ベイジアン学習 (赤本)
条件付き確率を使用した機械学習アルゴリズム。
ベイズの定理を利用して結果から原因を推論するのが特徴。
(例)スパムメールフィルタ、ECサイトのレコメンデーション
●ベイズの定理 (問題集)
\(\displaystyle{P(A|B)=\frac{P(B|A)P(A)}{P(B)}}\)
\(P(A|B)\):事後確率(問題集)(結果Bがわかっているもとでの原因Aの確率)
\(P(A)\):事前確率(問題集)(結果Bがわかる前の原因Aの確率)
\(P(B|A)\):尤度(問題集)(結果Bに対する原因Aのもっともらしさを表す)
●最尤推定(最尤法) (問題集)
尤度(観測されたデータが起こりうる確率)から、モデルの確率パラメータを推定する方法の1つ。
ニューラルネットワーク (公式、赤本、青本、問題集)
●単純パーセトプロン (公式、赤本、青本、問題集)
入力層と出力層のみ。
活性化関数にシグモイド関数を利用すると「ロジスティック回帰」になる。
また出力層の活性化関数としてステップ関数が用いられる。
●多層パーセトプロン (公式、赤本、青本、問題集)
入力層、隠れ層1層、出力層の3層構造。
●隠れ層 (問題集)
入力と出力を対応付ける関数に相当する。
中間層とも呼ばれ、複数の層を持つことが出来る。
活性化関数としてシグモイド関数やReLU関数がある。
●出力層 (問題集)
活性化関数として恒等関数やソフトマックス関数がある。
その他用語
統計的仮説検定(問題集) スパースなデータ(問題集)
教師なし学習
教師なし学習 (公式、赤本、青本、問題集)
正解ラベルがないデータを学習し、データに共通する特徴的な構造や法則を見つけることを目的とする。
大脳皮質の働きを模倣した学習法。
クラスタリング (赤本、青本、問題集)
データを複数のグループにまとめる。
次元削減 (赤本、青本、問題集)
データをより少ない変数で要約しようとする。
異常検知
正常な行為がどのようなものかを学習し、それと大きく異なるものを識別する。
SVMを基に、セキュリティシステムなどに使用されている。
その他の例
確率変数の密度推定(問題集) 独立成分分析 オートエンコーダ(自己符号化器)
教師なし学習の代表的な手法(アルゴリズム)
k-means法 (公式、赤本、青本、問題集)
クラスタ数kをあらかじめ指定する必要がある非階層的クラスタリング(問題集)の1つ。
各データが複数のクラスタを跨ぐことがないハードなクラスタリング。
階層的クラスタリング (問題集)
最も似ている組み合わせから順にクラスタにまとめていき、まとめていく過程が階層的な樹形図(デンドログラム(問題集))のように表せる手法。
分割型と凝縮型に分かれ、凝縮型では距離の近いものを1つのクラスタとして順にデータにまとめていく。
主成分分析 (公式、赤本、青本、問題集)
次元削減の手法の1つ。
データのばらつきを最も顕著に表現できるように、すなわち分散を最大化するように第一主成分を選択する。
●カイザー基準 (問題集)
使用する主成分の数を決定するための基準。
●オートエンコーダ (問題集)
⇒「ディープラーニングの概要」の「事前学習」を参照。
t-SNE法 (赤本)
高次元のデータを、自由度1のt分布を用いて2次元や3次元の低次元に圧縮する手法。
t:t分布、S:Stochastic(確率的)、N:Neighbor(隣接)、E:Embedding(埋め込み)
●t分布
スチューデントのt分布とも呼ばれる。
自由度によって分布の形が変化する。
t検定で利用されることがある。
手法の評価
学習データでモデルを構築しても、その他のデータ(未知のデータ)に対しても正しく予測できる能力(汎化性能(問題集))が無ければモデルの意味がない。
汎化性能を測る方法に、ホールドアウト法と交差検証法がある。
ホールドアウト法(Hold-out法) (公式、赤本、青本、問題集)
全データを訓練データとテストデータに分割。

交差検証法(k-分割交差検証) (公式、赤本、青本、問題集)
全データをk個に分割し、その内の1つをテストデータにする。
それを各分割したデータ分繰り返す。
データ量が少ない場合に効果的。
ホールドアウト法と比較して、汎用的に性能を確認できるという利点がある。

評価指標・他
回帰問題での評価指標
MSE(問題集):\(\displaystyle{\frac{1}{n}\sum_{i=1}^{n}(y_{i}-\hat{y}_{i})^{2}}\)
●RMSE(問題集):\(\sqrt{\text{MSE}}\)
2乗の項があるので、大きな誤差があると途端に値が大きくなる。
⇒大きな誤差を重要視したい(大きな誤差を許容したくない)場合に用いる。
●MAE(問題集):\(\displaystyle{\frac{1}{n}\sum_{i=1}^{n}|y_{i}-\hat{y}_{i}|}\)
2乗されないので、大きな誤差(外れ値)があってもRMSEほど値は大きくならない。
⇒大きな誤差を少なく見積もりたい(目的変数の外れ値にあまり影響されたくない)場合に用いる。
RMSLE(問題集):\(\displaystyle{\frac{1}{n}\sum_{i=1}^{n}(\log{y_{i}}-\log{\hat{y}_{i}})^{2}}=\frac{1}{n}\sum_{i=1}^{n}\left(\frac{\log{y_{i}}}{\log{\hat{y}_{i}}}\right)^{2}\)
正解ラベルと予測値の比率に着目したい場合に用いる。
決定係数(問題集):\(\displaystyle{R^{2}=1-\frac{\sum_{i=1}^{n}(y_{i}-\hat{y}_{i})^{2}}{\sum_{i=1}^{n}(y_{i}-\bar{y})^{2}}}\)
\(\bar{y}\)は目的変数\(y_{i}\)の平均。
0から1の値をとる。
正解ラベルの変動の内、モデルによって説明できる変動の割合を示す。
回帰分析などで、データに対する推定された回帰式の当てはまりの良さを表す。
分類問題での評価指標
混同行列 (公式、赤本、青本、問題集)
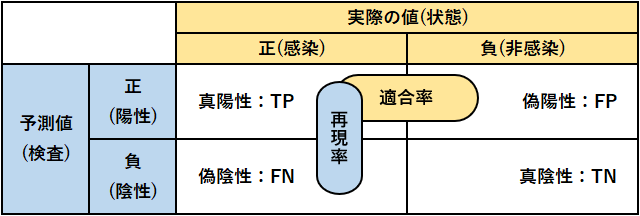
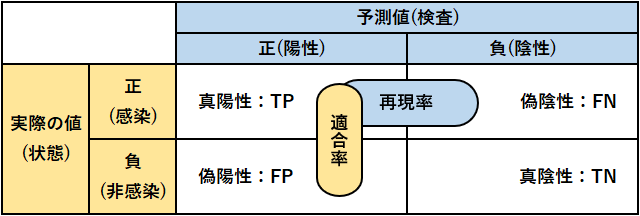
●正解率(公式、赤本、青本、問題集):\(\displaystyle{\frac{\text{TP}+\text{TN}}{\text{TP}+\text{FP}+\text{FN}+\text{TN}}}\)
●適合率(公式、赤本、青本、問題集):\(\displaystyle{\frac{\text{TP}}{\text{TP}+\text{FP}}}\)
陽性判定のうち実際に疾患を有する人の割合
●再現率(公式、赤本、青本、問題集):\(\displaystyle{\frac{\text{TP}}{\text{TP}+\text{FN}}}\)
疾患を有する人のうち正しく陽性判定できた割合
●F値(公式、赤本、青本、問題集):\(\displaystyle{\frac{2}{\frac{1}{\text{適合率}}+\frac{1}{\text{再現率}}}=\frac{2\times\text{適合率}\times\text{再現率}}{\text{適合率}+\text{再現率}}}\)
logloss (問題集)
二値分類の場合:\(\displaystyle{-\frac{1}{n}\sum_{i=1}^{n}\{y_{i}\log p_{i}+(1-y_{i})\log(1-p_{i})\}}\)
高い確信度を持った予測が誤ったときにペナルティが大きくなる。
ROC曲線 (問題集)
縦軸に真陽性率を、横軸に偽陽性率をとって両者の関係をプロットしたもの。
モデルがランダムな予測をする場合はROC曲線は傾き1の直線になる。
モデルの性能が上がるほど、曲線は左上に張り出す。
●AUC(問題集)
曲線の下側の面積。
曲線が直線の場合は0.5、モデルの性能が上がると1に近づく。
特徴量エンジニアリング(特徴量設計)
特徴量エンジニアリング(特徴量設計) (公式、赤本、問題集)
取得済みのデータから、データを加工して必要なデータを抽出すること。
マッピング
順序を持つ文字列のカテゴリーデータ(ドリンクのサイズS、M、Lなど)の場合、それぞれの値に対応する数値を辞書型データで用意し、これを数値に変化する方法。
エンコーディング (問題集)
数値で表せられないカテゴリを、何らかの変数に変換する作業。(「男」⇒「0」、「女」⇒「1」)
このとき置き換えた変数をダミー変数(問題集)という。
●one hot encoding (問題集)
そのカテゴリに所属しているか否かで0か1かを割り振る(ダミー変数は0と1のみ)。
学習単位
大量の訓練データ(サンプル)をいくつかのセットに等分し、セットごとに学習させてパラメータ(重み)を更新させる場合を考える。
イテレーション (赤本)
分割されたデータセットの数。⇒ 重みが更新された回数。
エポック (赤本)
訓練データを何回繰り返し学習したかを表す単位。
訓練データを1回一通り学習すると1エポックとなる。
バッチサイズ (赤本)
分割された1つのデータセットに含まれるデータ数。⇒1イテレーションに用いるデータ数。
汎化誤差
バイアス (赤本)
予測モデルと学習データとの差の平均を数値化したもの。
予測モデルが単純すぎる場合に大きくなる。
バリアンス (赤本)
予測モデルが複雑すぎることが原因で発生する。
ノイズ (赤本)
削除不能な誤差。
学習データ自体に余計なデータが混ざっている場合に大きくなる。
ディープラーニングの概要
特徴表現学習 (公式、問題集)
単に表現学習とも言う。
特徴量の加工・抽出かで学習器が行うこと。
ディープラーニングを抽象化した概念。
●分散表現(埋め込みモデル) (問題集)
単語を高次元ベクトルで表現する技術。
良い表現
何らかの意味で事象を抽象化したものであり、観測データの説明要因を捉えることで、一見自明ではない共通点を捉えることができるもの。
●ヨシュア・ベンジオ
ディープラーニングの父。
良い表現に共通する、世界に関する多くの一般的な事前知識として下記を提唱。
(1)滑らかさ
(2)複数の説明要因
(3)説明要因の階層的構造
(4)半教師あり学習
(5)タスク間の共通要因
(6)多様体
(7)自然なクラスタ化
(8)時間的空間的一貫性
(9)スパース性(データの分布のまばらさ)
(10)要因の依存の単純性
ディープラーニング (公式、赤本、青本、問題集)
隠れ層を増やしたニューラルネットワーク。
正確にはディープニューラルネットワーク(公式、青本)。
層が深いため深層学習とも呼ばれる。
観測データから本質的な情報である特徴量を自動的に抽出できるため、入力の良い内部表現を得ることができるようになった。
従来の機械学習手法と比べると、より複雑な関数を近似できるという性質も持っている。
損失関数(誤差関数)またはコスト関数を最小化することを目的とする。
●問題点
機械学習手法と比べて、学習に必要なパラメータ数と計算量が多い。
高性能は達成できるが、学習に従来以上の大量訓練データが必要になる。
誤差逆伝搬法 (公式、青本、問題集)
ニューラルネットワークを高速に学習させるために、出力に近い層から連鎖的に勾配を求めていく方法。
1980 年代にはすでに提案されていた。
活性化関数にシグモイド関数を使う場合、層を深くすると、層を経るごとに誤差が小さくなる勾配消失問題が起こる。
●勾配損失問題 (公式、青本、問題集)
誤差逆伝播法において、 入力層に近づくにつれて誤差が急速に小さくなってしまうことによって生じる。
モデルのパラメータの初期値に対して依存する。
対処法として、予め良い重みの初期値を計算する事前学習や、活性化関数に正規化線形関数(ReLU関数)を利用する方法などがある。
事前学習
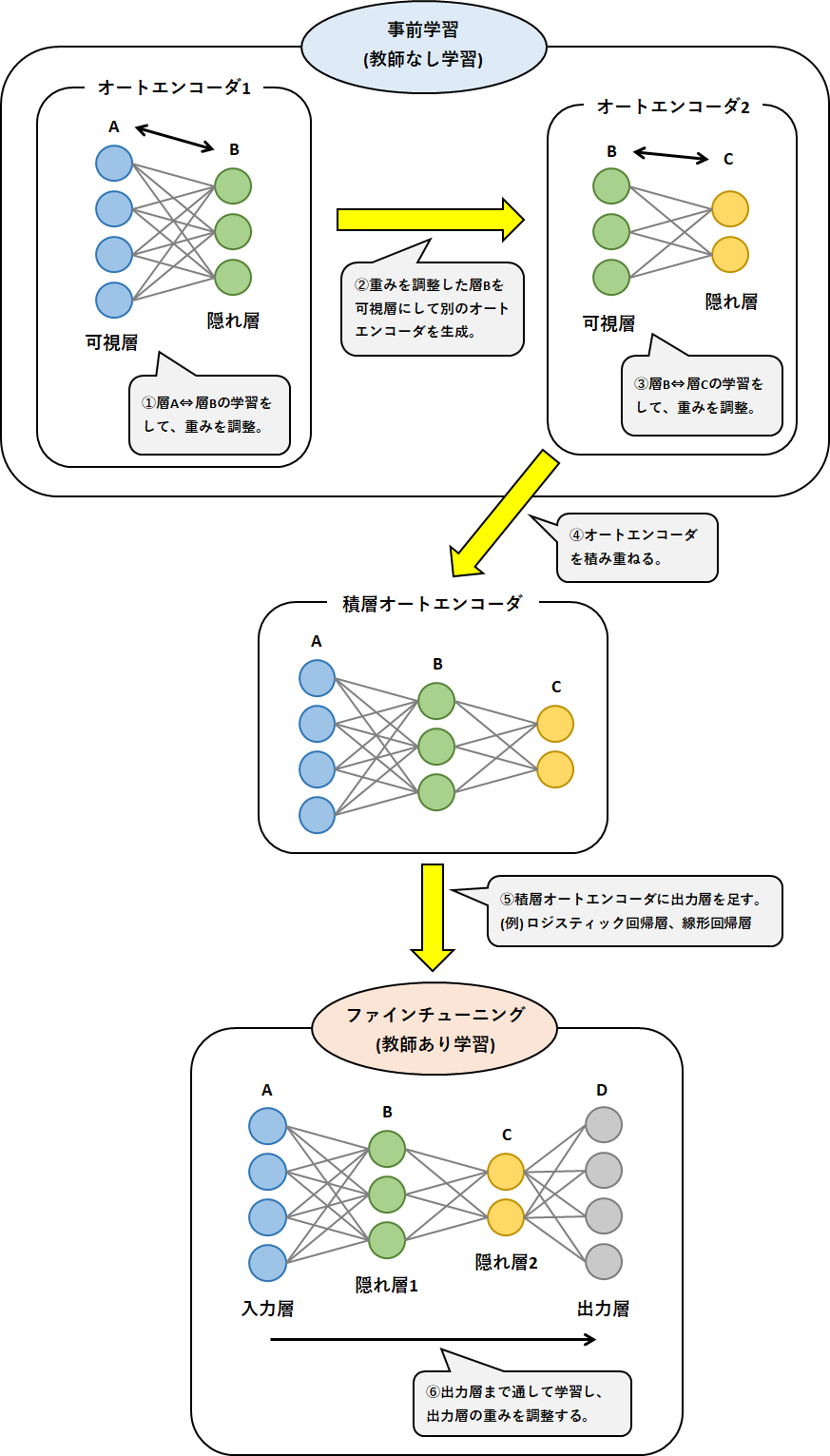
オートエンコーダ(自己符号化器) (公式、赤本、青本、問題集)
2006年にジェフリー・ヒントンが考案。
可視層(入力層と出力層)と隠れ層からなる2層のネットワーク(可視層を別々で捉えて3層と表現する場合もある)。
入力されたデータを一度圧縮し、同じ情報を出力する次元削減であるため、教師なし学習に分類される。
活性化関数に恒等写像を用いた場合の 3 層の自己符号化器は主成分分析(PCA)と同様の結果を返す。
情報量を小さくした特徴表現を獲得するため、入力層の次元よりも隠れ層の次元を小さくした上で、出力を入力に近づけるよう学習する。
代表的な応用例として仮想計測がある。
積層オートエンコーダ (公式、赤本、青本、問題集)
オートエンコーダの中でも特にディープラーニング用に改良したもの。
勾配消失問題を回避してニューラルネットワークの重みを学習するために、入力層に近い順から逐次的に学習を進める(層ごとの貪欲法)。
●ファインチューニング (公式、赤本、青本、問題集)
積層オートエンコーダの最後の工程。
オートエンコーダを積み重ねて教師なし学習を終えた(重みの調整が終了した)最後にロジスティック回帰層(または線形回帰層)を足し、全体で一気に学習をすること。
深層信念ネットワーク (公式、青本、問題集)
ジェフリー・ヒントンが考案。
積層オートエンコーダのオートエンコーダの部分に制限付きボルツマンマシンを採用した手法。
●制限付きボルツマンマシン (公式、青本、問題集)
可視層と隠れ層の2層のネットワーク。
隠れ層⇒可視層の学習がないことがオートエンコーダとの違い。
通常のボルツマンマシンでは隣層のユニット同士の結合に加えて同層のユニット同士が結合しているが、制限付きボルツマンマシンでは隣層のユニット同士の結合のみである。
ハード
ムーアの法則 (公式、青本、問題集)
「半導体のトランジスタの集積率は18か月ごとに倍になる」という経験則。
GPGPU (公式、赤本、青本、問題集)
GPUを用いて汎用的な演算を行わせるための技術。
NVIDIA社が提供する汎用並列コンピューティングプラットフォーム(プログラミング環境)にCUDAがある。
●TPU (公式、赤本、青本)
Googleが開発した、テンソル計算処理に最適化された演算処理装置。
バーニーおじさんのルール (公式、青本)
「モデルのパラメータ数の10倍のデータ数が必要」という経験則。
ディープラーニングの手法
活性化関数
シグモイド関数 (公式、赤本、青本、問題集)
\(\displaystyle{\text{sigmoid}(x)=\frac{1}{1+e^{-x}}}\)
\(0 \leq y \leq 1\)の範囲をとる。
二値分類問題の出力層の活性化関数として用いられる。
微分値が小さく(最大値0.25)、勾配消失が起きやすい。
ソフトマックス関数 (公式、赤本、青本、問題集)
多値分類問題の出力層の活性化関数として用いられる。
出力の総和が 1 になるため確率的な解釈が可能になる。
tanh関数(ハイパボリックタンジェント関数、双曲線正接関数) (公式、赤本、青本、問題集)
\(\displaystyle{\tanh(x)=\frac{e^{x}-e^{-x}}{e^{x}+e^{-x}}}\)
ニューラルネットワークの隠れ層で用いられる活性化関数の1つ。
シグモイド関数を式変形(線形変換)することで得られる。
微分値がシグモイド関数より大きい(最大値1)ため、シグモイド関数と比較して勾配消失が緩和される。
ReLU関数(正規化線形関数、ランプ関数) (公式、赤本、青本、問題集)
\(\displaystyle{\text{max}(0,x)=\begin{cases}x\quad(x\geq 0)\\ 0\quad(x\leq 0)\end{cases}}\)
ニューラルネットワークの隠れ層の活性化関数として、多くの種類のモデルでよく使われている活性化関数。
微分不可能な点が存在する。
●Leaky ReLU関数 (公式、青本)
\(x<0\)においてわずかに傾きを持ったReLU関数。
●Parametric ReLU (公式、青本)
Leaky ReLU関数の\(x<0\)部分の直線の傾きを学習によって最適化させる。
●Randomized ReLU (公式、青本)
Leaky ReLU関数の\(x<0\)部分の直線の傾きをランダムに試す。
Maxout (赤本)
複数の線形関数を1つにした構造を持ち、それらの中での最大値を利用する。
誤差関数(損失関数) (赤本)
●平均二乗誤差関数 (赤本、青本)
回帰問題に用いられる。
●交差エントロピー誤差関数 (赤本、青本)
多クラス分類(多値分類)に用いられる。
●KLダイバージェンス (赤本、青本)
オートエンコーダに用いられる。
2つの確率分布がどの程度似ているかを表す尺度である。
非負の値をとり、2つの確率分布が同じ場合、値は0となる。
勾配降下法
勾配降下法 (公式、赤本、青本、問題集)
損失関数の値をできるだけ小さくするパラメータを見つける方法の1つ。
関数の勾配にあたる微分係数に沿って降りていくことで、関数の最小値を求める。
ここにおいて学習率は「勾配に沿って一度にどれだけ降りていくかを設定するもの」になる。
真の解(本当の最小値)を大域最適解(公式、青本、問題集)、それ以外の局所的な解を局所最適解(公式、青本、問題集)と呼ぶ。
種類としてはバッチ勾配降下法、ミニバッチ勾配降下法、確率的勾配降下法などがある。
●問題点
微分係数をモニタリングするため、上に凸、下に凸に関わらず微分係数が0になるとどこでも探索をストップしてしまう。
谷での振動、プラトー(鞍点などの停留点に到達して学習が停滞している状態)へのトラップ、局所的最適解への収束などの問題がある。
パラメータの勾配を数値的に求めると計算量が膨大となってしまう問題があり、このような問題を避けるために誤差逆伝播法が利用される。
対象の関数の形がある分布や方向に依存すると非効率な経路でパラメータを探索してしまい、学習に時間がかかってしまう。
●学習率 (公式、赤本、青本、問題集)
学習率が小さいと、収束に時間がかかり、コスト関数の最終的な値は小さくなる。また、局所的最適解から抜け出せずそのまま収束してしまうことがある。
反対に学習率が大きい場合は、収束するのが早くなるが、コスト関数は大きな値になりやすい。
勾配降下法の具体的な手順
1.重みとバイアスを初期化する。
2.データ(ミニバッチ)をネットワークに入力し出力を得る。
3.ネットワークの出力と正解ラベルとの誤差を計算する。
4.誤差を減らすように重み(バイアス)を修正する。
5.最適な重みやバイアスになるまで繰り返す。
最急降下法 (青本、問題集)
バッチ勾配降下法とも呼ぶ。
データセットを全てネットワークに入力して誤差を求め、パラメータを更新することを繰り返す。
ミニバッチ勾配降下法
データセットの一部をネットワークに入力して誤差を求める。
最急降下法と確率的勾配降下法の中間に位置する方法。
確率的勾配降下法(SGD) (赤本、青本、問題集)
オンライン勾配降下法とも呼ぶ。
パラメータ\(x\)を更新するための勾配を求める際、データは全データの中からランダムに1つ抜き出して利用する。
パラメータの更新式は「\(x_{\text{new}}=x_{\text{old}}-\)(学習率)\(\times\)(抜き出したデータを使って求めた勾配)」となる。
●モーメンタム (公式、赤本、青本、問題集)
SGDの改良形の1つ。
以前に適用した勾配の方向を現在のパラメータ更新にも影響させる。
力学の考え方を用いて、パラメータの更新に慣性的な性質を持たせ、勾配の方向に減速・加速したり、摩擦抵抗によって減衰したりしていくようにパラメータを更新していく。
AdaGrad (公式、赤本、青本、問題集)
求めた勾配によってパラメータ毎の学習率を自動で調整するもの。
(SGDでは学習率は人が決め、全てのパラメータに対して一律に適用される。)
勾配を2乗した値を蓄積し、すでに大きく更新されたパラメータほど更新量(学習率)を小さくする。
●RMSProp (公式、赤本、青本、問題集)
AdaGradの学習のステップが進むと、すぐに学習率が小さくなって更新されなくなる問題点を改良したもの。
勾配の2乗の指数移動平均を蓄積することにより解決した。
●AdaDelta (公式、赤本、青本)
AdaGradの発展形。
過去全ての勾配の2乗を蓄積するのではなく、過去の勾配を蓄積する範囲を制限している。
●Adam (公式、赤本、青本、問題集)
RMSPropの更なる改良形。
移動平均で振動を抑制するモーメンタムと、学習率を調整して振動を抑制するRMSPropを組み合わせている。
勾配の平均と分散をオンラインで推定し利用する。
さらなるテクニック
ドロップアウト (公式、赤本、青本、問題集)
ニューラルネットワークの学習において過学習を防ぐ方法の1つ。
学習の際、一定の確率でランダムにノードを無視して学習する。
学習中のニューラルネットワークの形は更新の度に異なる形となるため、結果として複数のネットワークが同時に学習されるアンサンブル学習と等価になる。
よって複数のネットワークの中のいくつかが過学習を起こしても、全体としてはその影響を抑えられる。
early stopping(初期停止、早期終了) (公式、赤本、青本、問題集)
過学習を防ぐ方法の1つ。
過学習を起こす前に、学習を早めに切り上げて終了する。
よって学習を打ち切るタイミングは、テストデータに対する誤差関数の値が上昇傾向に転じたときが最適と考えられる。
ニューラルネットワークの種類に縛られず、あらゆる種類の学習に容易に適応できるのが利点。
●ノーフリーランチ定理 (公式、問題集)
「あらゆる問題に対して性能の良い汎用最適化戦略は理論上不可能である」ことを示す定理。
early stoppingはあらゆる種類の問題に対して適用可能なため、ノーフリーランチ定理に反する。
ジェフェリー・ヒントンはこれを意識し、early stoppingを「Beautiful FREE LUNCH」と表現した。
データの前処理
●正規化
データのスケールを揃えるなどして調整すること。
各特徴量を0から1の範囲に変換する処理が最も一般的。
●標準化
データを平均を0に分散を1に規格化する方法。
●白色化 (公式、問題集)
学習前のデータの前処理の手法の1つ。
各特徴量(パラメータ)を無相関化した上で標準化(平均0,分散1)する処理。
●主成分分析(PCA)
重みの初期値
ニューラルネットワークにおいて、活性化関数を通ることでデータの分布が崩れることがある。
ネットワークの大きさと活性化関数の種類に応じて、重みの初期値として適切な乱数が存在する。
●Xavierの初期値 (公式、赤本、青本、問題集)
\(\sqrt{1/n}\)の標準偏差をもつガウス分布。
活性化関数がシグモイド関数やtanh関数の場合に用いる。
●Heの初期値 (公式、青本、問題集)
\(\sqrt{2/n}\)の標準偏差をもつガウス分布。
活性化関数がReLU関数の場合に用いる。
バッチ正規化 (公式、赤本、青本、問題集)
ニューラルネットワークにおいて、活性化関数を通ることでデータの分布が崩れる問題(内部共変量シフト)への対処法の1つ。
ニューラルネットワークの各層で、前の層から伝わってきたデータに対してもう一度正規化を実施する。
さらに、過学習が起きにくくなる、重みの初期値に対する依存性を下げるといった効果もある。
ハイパーパラメータの決め方
●グリッドサーチ (赤本)
適切だと考えられるパラメータの候補値を複数用意し、それらの値の組み合わせを全通り総当たりで行い、最も良いハイパーパラメータを探す方法。
●ランダムサーチ
考えられるパラメータの範囲を決め、ランダムにパラメータを組み合わせて学習させ、最も良いハイパーパラメータを探す方法。
●ベイズ最適化 (赤本)
過去の試行結果から次に行う範囲を、確率分布を用いて計算する手法。
ハイパーパラメータを含め最適化問題とする。
CNN:畳み込みニューラルネットワーク
畳み込みニューラルネットワーク(CNN) (公式、赤本、青本、問題集)
データに潜む空間的構造をモデル化する。
畳み込み層とプーリング層を積み上げた構成をしている。
畳み込み (公式、赤本、青本、問題集)
以下の手順で実施する。
① 画像に対してカーネルを重ね合わせ、重なり合った画像の要素とカーネルの要素の積を計算。
② 各要素の積を足し上げる。
③ 一定のストライドでカーネルを移動させる。
④ ①~③を画像全体で繰り返し、新たな二次元の出力(特徴マップ)を得る。
カーネルのサイズ、カーネルの数値、ストライド、パティングの有無で、同じ入力画像でも異なる特徴マップが得られる。
その中でもカーネルの数値は学習の中で最適化できるが、その他は学習前に人の手で決定されるハイパーパラメータとなる。
●カーネル(フィルタ) (公式、赤本、青本、問題集)
畳み込みの際に画像に適用する数字表。
畳み込み層ではカーネル内部の値をパラメータとして学習する。
●ストライド (青本、問題集)
畳み込みにおいてカーネルを移動させる幅のこと。
●特徴マップ (公式、赤本、青本、問題集)
画像を入力データとして畳み込みをした結果得られる新たな二次元の出力。
●パディング (赤本、青本)
出力画像のサイズを調整するために元の画像の周りを固定の値で埋めること。
プーリング (公式、赤本、青本、問題集)
画像や特徴マップなどの入力を小さく圧縮する処理。
具体的な方法として、特定のサイズ領域ごとに最大値を抜き出す最大プーリングや、平均値をとる平均プーリング、値をp乗しその標準偏差をとるLpプーリングがある。
同じものを写しているがわずかに位置が異なる2つの画像があったとしても、この処理によりニューラルネットワークは同じ特徴量を見つけ出せると期待できる。
またプーリング自体は「最大値をとる」または「平均をとる」といった決まった計算しか実行しないため、プーリング処理を実施するプーリング層には学習によって最適化されるパラメータが存在しないという特徴がある。
全結合層 (公式、赤本、問題集)
入力画像に対して畳み込みやプーリングを実施して特徴マップを得た後に、その特徴マップを1次元の数値に変換し、変換した数値を入力値として最終的な1次元の出力を得る層。
2次元の入力画像に対応付けられている正解ラベルが1次元であることから、正解ラベルとの比較をするための1次元予測値を得るために設けられる。
ゆえに全結合層は多層パーセトプロンに用いられる層と同じ構造をしている。
CNNの全結合層と比較して、畳み込み層のパラメータ数は極めて少ない。
これは重み共有によって有用な特徴量を画像の位置によって大きく変化させないため、パラメータ数が減り、計算量が少なくなるためである。
●重み共有 (赤本)
畳み込み層における重みを全ユニットで統一すること。
●Global Average Pooling(GAP、グローバルアベレージプーリング) (公式、問題集)
全結合層への前段階として、分類したいクラスと特徴マップを1対1対応させ、各特徴マップに含まれる値の平均を取ることで画像を1次元化する手法。
全結合層のみを使う場合と比べてモデルの持つパラメータ(重み)が少なくなるため、過学習が起きにくくなる。
転移学習 (公式、赤本、青本、問題集)
データが少量しかないなどの理由で、対象のタスクを学習させることが困難なときに用いられる手法。
学習済みのネットワークに新たに層を付け足し(または置き換え)、その新たな層のみを学習(パラメータ調整)することで新たな問題に対応する。
新たに付け足した層だけでなく、利用した学習済みモデルに含まれるパラメータも同時に調整する場合はファインチューニングと呼ぶ。
画像データを用いるモデルで転移学習やファインチューニングを実施する際は、学習済みモデルの出力層の後に新たな層を追加、もしくは置き換えると良い。
(入力層付近は画像データの抽象的な特徴量を学習するため、入力層付近のパラメータはあらゆる種類の画像分類問題に応用できると考えられるため。)
ただし、利用元のモデルと転移先のモデルでデータの種類(ドメイン)の関連性が低い場合は効果が薄い。
蒸留 (赤本、青本)
大きなニューラルネットワークなどの入出力をより小さなネットワークに学習させる技術。
すでに学習されているモデル(教師モデル)を利用して、より小さくシンプルなモデル(生徒モデル)を学習させる手法。
生徒モデルを単独で学習させる場合よりも過学習を緩和することができる。
ネオコグニトロン (公式、問題集)
単純型細胞(S細胞)と複雑型細胞(C細胞)の2つの細胞の働きを初めて組み込んだCNNのモデル。
「特徴抽出を行うS細胞層」と「位置ズレを許容するC細胞層」を交互に多層に接続した構造をしている。
1980年代に福島邦彦が提唱。
画像データの前処理
●グレースケール化
カラー画像を白黒画像に変換して計算量を削減する。
●平滑化
細かいノイズの影響を除去する
●ヒストグラム平均
画素ごとの明るさをスケーリングする
●局所コントラスト正規化
減算正規化と除算正規化の処理を行う。
OpenCVなどの画像処理に特化したライブラリで行うことができる。
RNN:リカレントニューラルネットワーク
リカレントニューラルネットワーク(RNN) (公式、赤本、青本、問題集)
データに潜む時間的構造をモデル化する。
RNNでは、過去の入力による隠れ層の状態を、現在の入力に対する出力を求めるために用いる。
このように、過去の入力の情報が現在の入力に影響を与えることができる再帰的な構造を持っているため、RNNは時系列データを処理するのに適していると言える。
時間軸に沿って深いネットワーク構造を持つため、勾配消失問題が起きやすい。
さらにネットワークにループ構造が含まれるため、中間層が 1 層であっても勾配消失問題が起きてしまう。
BPTT(BackPropagation Through Time、通時的誤差逆伝搬) (赤本、青本、問題集)
過去の時系列をさかのぼりながら誤差を計算していく手法。
計算される勾配に対して、時系列の古いデータほど勾配消失しやすいという特徴がある。
LSTM (公式、赤本、青本、問題集)
ケプラー大学のゼップ・ホフレイターが、RNNの勾配消失問題を解決する手法として提案。
「CEC(Constant Error Carousel)という情報を記憶する構造」と「データの伝搬量を調整する3つのゲート(忘却ゲート、入力ゲート、出力ゲート)を持つ構造」を有する。
この2つの構造をまとめてLSTMブロックと呼ぶ。
入力重み衝突、出力重み衝突を解決するために上記のような構造をしている。
計算量が多いという短所がある。
機械翻訳や画像キャプション生成などに応用できる。
●入力重み衝突 (問題集)
現在の入力に対し過去の情報の重みは小さい必要がある。
しかし、将来の為に大きな重みを残しておく必要があるという矛盾が、新しいデータの特徴を取り込むときに発生すること。
●出力重み衝突 (問題集)
現在の入力に対し過去の情報の重みは小さい必要がある。
しかし、将来の為に大きな重みを残しておく必要があるという矛盾が、現在の状態を次時刻の隠れ層(中間層)へ出力するときに発生すること。
●GRU(Gated Recurrent Unit) (公式、赤本、青本、問題集)
LSTMを軽量化したモデルの1つ。
リセットゲートと更新ゲートという2つのゲートを用いた構造を持つブロックの組み合わせによって構成されている。
双方向RNN(Bidirectional RNN:BiRNN) (公式、赤本、青本、問題集)
2つのRNNが組み合わさった構造をしており、一方はデータを時系列通りに学習し、もう一方は時系列を逆順に並び替えて学習を行うモデル。
過去と未来の両方の情報を踏まえた出力ができるようになると期待できる。
RNN-Encoder-Decoder (公式、赤本、問題集)
入力の時系列に対して出力も時系列として予測したいという問題(sequence-to-sequence,seq2seq)を解決するために考えられたモデル。
エンコーダ(Encoder)とデコーダ(Decoder)と呼ばれる2つのRNNから構成される。
エンコーダでは入力される時系列データから固定長ベクトルを生成し、その後デコーダでは固定長ベクトルから時系列データを生成する。
固定長ベクトルの長さは、入力の時系列データの長さに依らず一定である。
Attention (公式、赤本、問題集)
RNN-Encoder-Decoderの短所(固定長ベクトルに入る情報量が制限される問題)を克服したモデル。
入力データの一部分に注意するような重みづけを行うことで重要な情報を取り出せるようにした。
「過去の入力のどの時点がどれくらい影響を持っているか」を直接的に求めることで入出力データ間の対応関係を求めている。
●GNMT
Attentionの応用事例。
Googleは2016年からこれをGoogle翻訳に取込、翻訳の精度を向上させた。
RNNにおける教師強制
教師データがあることで学習の収束が早くなる可能性がある。
教師データが使えない状況では出力に誤差が生じる可能性がある。
訓練時に入力として、前の時間の正解値(目標値)を利用する。
深層強化学習
強化学習 (公式、赤本、青本、問題集)
エージェントが自身の報酬を最大化するような行動指針を獲得する。
大脳基底核の働きを模倣した学習法。
状態遷移を考慮することができる。
個々の行動に対する報酬の最大化を目指すのではなく、一連の行動によって得られる報酬の最大化を行う。
具体的には、一連の行動選択から得た報酬を参考に個々の行動選択を改善する。
行動の組み合わせ自体を学習するのではなく、行動選択の仕方を学習するということに注意。
行動選択を行った後に報酬が得られない環境でも方策を学習できる(例えば囲碁のように勝敗が決したときのみ報酬が得られる場合)。
●問題点
正解データ付きの訓練データを用意する必要がないが、一般的に学習には時間がかかる。
学習時間の問題
⇒理論的には無限に学習するが、実世界では全てが限られている。ロボットの場合、無限の試行を繰り返すことができず、損耗し、実験の続行が困難になる。そこで人間側がタスクを上手く切り分けてやさしいタスクからの学習をすることが期待される。
マルチエージェント応用の問題
⇒例として、2 体のロボット同士で学習を開始させようとすると、お互いに初期状態であるタスクについての何も知識がない状態だと、学習過程の不安定化が見られる。
深層強化学習 (公式、赤本、青本、問題集)
深層学習(ディープラーニング)における隠れ層(中間層)の出力を縮約表現とみなす。
(例)ボードゲームの盤面を画像とみなし、畳み込みニューラルネットワークを用いることで状態を縮約する。
ニューラルネットワークを用いて状態の重要な情報のみを縮約表現することで、状態数が多い問題に対しても強化学習が適用できるようになった。
モデルベースの手法 (問題集)
環境に対する情報が完全である場合に適応できる。
状態遷移確率と報酬関数が既知の場合に最適ベルマン方程式を用いて最適価値関数を求めて報酬和を最大にする。
価値関数ベースの手法 (問題集)
報酬の期待値を状態や行動の価値計算に反映する。
ある状態である行動をとった後に得られる報酬の期待値を算出し、期待値の大きい状態に到達するように、期待値の大きい行動をとるようにすることで得られる報酬和を最大化する。
方策ベースの手法 (問題集)
現時点の方策で計算した報酬の期待値と方策を見比べ、どのように方策を変化させれば報酬の期待値が大きくなるかを直接計算する。
ある状態に対してある行動を起こす確率をパラメトリックな関数fで表現する。
この関数を用いて一連の行動による報酬の期待値を求め、期待値が大きくなるように関数fのパラメータを変化させることを繰り返して、報酬和を最大化する。
Q値(状態行動価値) (青本)
エージェントが選択した行動の最終的な報酬の期待値。
強化学習ではQ値が最大になるように学習する。
●Q関数(状態行動価値関数) (青本)
\(Q(状態,行動)=報酬+\gamma\text{Max}(Q(次の状態,次にとれるすべての行動))\)
Q値を求める関数。
\(\text{Max}(Q(次の状態,次にとれるすべての行動))\)は、次の状態と、次でとりうる全ての行動の内、Q値が最大のもの。
\(\gamma\)は割引率であり、\(0<\gamma\leq 1\)の範囲をとる。
割引率により、報酬は未来にいくほど小さくなる。
Q学習 (公式、赤本、青本、問題集)
価値ベースの強化学習手法の1つ。
状態と行動の組に対してその後得られる報酬和の期待値(Q関数)を推定し、期待値が最大である行動を選択するアルゴリズム。
Deep Q Network(DQN) (公式、赤本、青本、問題集)
Q関数の関数近似に畳み込みニューラルネットワークを用いた手法。
ニューラルネットワークは、入力に状態を受け取り、Q関数を近似する。
行動選択などの制御はあらかじめ設定した方策によって行う。
●Experience replay (問題集)
DQNを用いる際、行動系列から得られた報酬をもとにネットワークの重みを更新する。
重みの更新は状態遷移に強い相関を受けるため学習が安定しない。
この問題に対して状態、行動と報酬の組を記録しておいたものからランダムサンプリングして重みを更新する。
●Dueling Network (公式、問題集)
Q関数をニューラルネットワークで近似する際に、状態のみからで計算できる部分と行動のみから計算できる武運を別々に計算することで、効率よくQ関数を学習できる。
●Reword clipping (問題集)
ニューラルネットワークのパラメータには報酬の値に大きく影響を受ける。
報酬の値を-1,0,1に限定したり、-1,1の範囲に限定したりすることで、ニューラルネットワークの学習を安定させる。
●Double DQN (公式、問題集)
Q関数の更新には、更新を行うQ関数の状態の次の状態のQ関数のうち、最大の値を持つものを目標値とする。
そのため、誤差の上方向に影響を受ける傾向がある。
これを防ぐためにQ関数の更新を行うネットワークと次の状態のQ関数のうち、更新に用いるQ関数を選ぶネットワークを使う。
●Categorical DQN (公式、問題集)
Q関数はある状態とある行動により今後得られる期待収益値であるが、期待収益を離散確率分布とすることで学習を安定させたり、期待収益の分散や多峰性分布が表現できる。
方策勾配法 (問題集)
方策反復法の1つの手法である。
方策勾配定理に基づき実装される。
方策をあるパラメータで表される関数とし、そのパラメータを学習することで、直接方策を学習していく。
方策を設定して一連の行動を実行し、得られた報酬によって方策を評価して直接方策を改善する。
連続的な行動も選択可能。
価値反復法
行動価値と状態価値の2種類の価値を定義する。
TD誤差が可能な限り小さくなるまで学習を行う。
Sarsaはアルゴリズムの代表例の1つである。
モンテカルロ木探索(MCTS) (公式、問題集)
AlphaGo以前のゲームAIの作成方法。
ある状態から行動選択を繰り返して報酬和を計算するということを複数回行った後、報酬和の平均値をある状態の価値とする価値推定方法。
AlphaGOに用いられるニューラルネットワーク
●Supervised Learning Policy Network(SL Policy) (問題集)
人間の棋譜の遷移状態を学習させることで1つ次の手を予測し勝ちに繋がりやすい状態を列挙する。
入力データ:現在の盤面の状態、出力データ:次の盤面の状態、教師データ:人間の棋譜
●Rollout Policy (問題集)
SL Policyの性能を落とす代わりに計算速度を向上させた手法。
入力データ:現在の盤面の状態、出力データ:次の盤面の状態、教師データ:人間の棋譜
●Reinforcement Learning Policy Network(RL Policy) (問題集)
SL Policyのネットワーク同士の対戦による学習で予測性能を向上させた手法。
入力データ:現在の盤面の状態、出力データ:次の盤面の状態、教師データ:RL PolicyとSL Policyの対戦の勝敗
●Value Network (問題集)
ある盤面からRL PolicyとRollout Policyのネットワークを用いて勝敗がつくまでゲームを進め、この勝敗をもとに盤面の勝利確率を学習させ、予測する。
入力データ:現在の盤面の状態、出力データ:勝率、教師データ:RL Policyで作成した棋譜
深層強化学習アルゴリズムの発表された順
1. AlphaGo Fan
2. AlphaGo Zero (公式)
棋譜を全く必要としない、完全に自己対局のみで学習を進める。
3. AlphaZero
4. AlphaStar
A3C
強化学習のアルゴリズムの1つ。
sim2real
強化学習において、現実世界とシミュレーションのギャップを様々な方法で埋めるアプローチ。
深層生成モデル
深層生成モデル (公式、赤本、青本、問題集)
ディープラーニングを、新たなデータを生成するというタスクに用いたモデル。
訓練データからそのデータの特徴を学習し、類似したデータを生成することができる。
変分オートエンコーダ(Variational Autoencoder:VAE) (公式、赤本、青本、問題集)
深層生成モデルの1つで、オートエンコーダに改良を加えたモデル。
オートエンコーダの潜在変数に確率分布を導入している。
エンコーダ部分では入力データを、入力データを生成するなにかしらの分布の平均と分散に変換するような学習を行う。
敵対的生成ネットワーク(Generative Adversarial Network:GAN) (公式、赤本、青本、問題集)
画像生成分野でよく使用される深層生成モデルの1つ。
ジェネレータが偽物のデータを生成し、ディスクリミネータがその偽物のデータが本物か偽物か判定する。
ジェネレータが、十分精度の高いディスクリミネータを騙せる画像を生成できるなら、ジェネレータが本物に近い画像を生成できていると言える。
この学習をうまく進めるには、ジェネレータとディスクリミネータの学習を少しずつ交互に進める必要がある。
●ジェネレータ(generator) (公式、赤本、青本、問題集)
騙し手。生成ネットワーク。
もととなるデータやランダムなノイズといった入力を受け取り、偽物のデータを出力する。
●ディスクリミネータ(discriminator) (公式、赤本、青本、問題集)
判定者。識別ネットワーク。
本物のデータもしくはジェネレータが生成した偽物のデータを受け取り、これらのデータの真偽を判定、出力する。
●DCGAN(Deep Convolutional GAN) (公式、青本)
GANにCNNを適用したモデル。
●その他応用アルゴリズム
・StyleGAN
・AttnGAN
・CycleGAN
WaveNet (問題集)
音声生成の分野に大きな影響を与えたモデル。
最初の入力から次の出力を次々に予測していくといったアプローチをベースにCNNで構成されいる。
ディープラーニングの研究分野
画像認識・生成
ILSVRC (問題集)
ImageNetと呼ばれるデータセットを使った画像認識の分類精度を競う競技会。
画像分類 (問題集)
画像がどのクラスに所属するのかを予測する。
●LeNet (公式、赤本、問題集)
畳み込み層とプーリング層を交互に組み合わせたCNNモデル。
1998年にヤン・ルカンが提唱。
初めて多層 CNN に誤差逆伝播法を適用した。
●AlexNet (問題集)
2012年ILSVRC第1位。
画像認識コンペILSVRCにて初めて登場した画像認識CNNモデル。
ジェフリー・ヒントン教授らのチームによって発表された。
●GoogLeNet (問題集)
2014年ILSVRC第1位。
Inceptionモジュール(インセプションモジュール)という小さなネットワークを積み上げた構造をしている。
全結合層の代わりにGlobal Average Poolingを採用している。
・Inceptionモジュール(インセプションモジュール)
小さなネットワークを1つのモジュールとして定義している。
ネットワークを分岐させ、サイズの異なる畳み込みを行う。
複数のフィルタ群によるブロックから構成される。
●VGG16 (問題集)
2014年ILSVRC第2位。
オックスフォード大学のチームが発表。
13層の畳み込み層と3層の全結合層の合計16層で構成されるCNNモデル。
3×3のサイズの小さな畳み込みフィルタを用いて計算量を減らした上で、層を深くした。
●VGG19 (問題集)
19層のネットワークからなるアーキテクチャ。
●ResNet (問題集)
2015年ILSVRC第1位。
最大152層から構成されている。
出力を入力と入力からの差分の和で表現し、求めたい関数と入力との差である残差を学習するようにした。
層を飛び越えた結合(スキップコネクション)を持つ構造をしている。
畳み込み層とショートカットコネクションを組み合わせた残差ブロックを導入している。
入力層から出力層まで伝播する値と入力層の値を足し合わせたモデルで、この方法によって、入力層まで、勾配値がきちんと伝わり、今では 1000 層といったかなり深い構造でも学習が可能となった。
●DenseNet (問題集)
2016年に発表されたモデル。
前方の各層からの出力すべてが後方の層への入力として用いられるのが特徴。
Dense Blockと呼ばれる構造を持つ。
●EfficientNet (問題集)
2019年にGoogleから発表されたモデル。
これまで登場したモデルよりも大幅に少ないパラメータ数でありながらSoTA(State of the Art=最高水準)を達成。
モデルの深さ、広さ、入力画像の大きさをバランスよく調整しているのが特徴。
物体検出 (問題集)
画像に写っている物体をバウンディングボックスと呼ばれる矩形の領域で位置やクラスを認識する。
●R-CNN (問題集)
2014年に発表されたCNNを用いた物体検出モデル。
人間が行う物体認識のように、領域ごとに特徴量を抽出する。
●Fast R-CNN
R-CNNに比べCNNの演算回数を削減できる可能性が高い。
●Faster R-CNN (問題集)
2015年にMicrosoft社が開発した物体検出モデル。
●Mask R-CNN
これを用いると、身体のポーズの検出も可能となる可能性が高い。
●YOLO (問題集)
同系統の1ステージ型の検出アルゴリズム。。
物体検出手法の1つで、検出と識別を同時に行うのが特徴。
●SSD (問題集)
物体検出の手法の1つ。
YOLOと同系統の1ステージ型の検出アルゴリズム。
小さなフィルタサイズのCNNを特徴マップに適応することで、物体のカテゴリと位置を推定できる。
画像セグメンテーション (問題集)
画像に写っているものをピクセル単位で領域やクラスを認識する。
●セマンティックセグメンテーション (問題集)
物体領域を種類ごとに抽出する。
画像内の全画素にラベルやカテゴリを関連付ける。
●インスタンスセグメンテーション (問題集)
個別の物体領域を抽出する。
●SegNet (問題集)
2017年に提案されたセマンティックセグメンテーションを行う手法の1つ。
入力画像から特徴マップの抽出を行うエンコーダと、抽出した特徴マップと元の画像のピクセル位置の対応関係をマッピングするデコーダで構成される。
●U-Net (問題集)
セマンティックセグメンテーションを行う手法の1つ。
完全結合ネットワーク(FCN)の一種で、畳み込まれた画像をデコードする際にエンコードで使った情報を用いるのが特徴。
画像生成 (問題集)
敵対生成ネットワーク(GAN)や変分オートエンコーダ(VAE)などを利用し、画像を生成する。
●VAE (問題集)
●GAN (問題集)
●DCGAN (問題集)
●pix2pix (問題集)
特徴量(特徴マップ)からの画像を生成
CNNと逆の操作を行うことで画像を生成する。
これらの構造を用いるタスクの例として画像セグメンテーションがある。
●逆畳み込み層
畳み込み層の逆操作。
●アンプーリング層
プーリングの逆操作。
完全結合ネットワーク(FCN)
「全層畳み込みネットワーク」とも呼ぶ。
すべての層を畳み込み層としてネットワークを構成するため、入力する画像のサイズに制限がないというメリットがある。
セマンティック・セグメンテーションに応用されている。
U-netはFCNの1つである。
ディープフェイク
GANなどの深層学習技術を用い合成され、偽物とは容易に見抜けないほど作り込まれた合成メディア。
自然言語処理
形態素解析 (問題集)
形態素と呼ばれる、言語で意味を持つ最小単位まで分割し、解析する手法。
単純に単語を分割するだけでなく、それぞれの形態素の品詞などの判別も行う。
辞書を用意しておくことで解析精度を向上させることが出来る。
Transformer (問題集)
Googleが2017年に発表した論文「Attention Is All You Need」で登場した言語モデル。
Attentionを使用している。
●GPT-2 (問題集)
OpenAIが2019年に発表したTransformerベースのテキスト生成モデル。
800万のWEBページを学習している。
●GPT-3
OpenAIが2020年に公開した教師なしのTransformer言語モデル。
BERT (問題集)
2018年にGoogleが発表。
双方向Transformerを使ったモデルで、事前学習に特徴がある。
発表当時のモデルの中でSoTA(State of the Art=最高水準)を達成した。
●MLM(Masked Language Model) (問題集)
BERTに用いられている事前学習のタスク。
文中の複数個所の単語をマスクし、本来の単語を予測する。
●NSP(Next Sentence Prediction) (問題集)
BERTに用いられている事前学習のタスク。
2文が渡され、連続した文かどうかを判定する。
●ALBERT (青本)
2019年9月に発表。
BERTを軽量化・高速化したもの。
GSG(Gap Sentence Generation) (問題集)
PEGASUSというモデルに用いられている事前学習タスク。
複数個所の文をマスクし、本来の文を予測する。
マスク部分の決定はランダム以外の方法で決める。
トピックモデル (問題集)
文書や単語に潜む潜在的なカテゴリを説明するモデル。
文書以外にも、例えば通販サイトにおいて、顧客の購買履歴から商品の潜在的がカテゴリを知ることが出来る。
●潜在的ディリクレ配分法(LDA:Latent Dirichlet Allocation) (赤本、問題集)
トピックモデルの代表的モデル。
1つの文書には複数の潜在トピックが存在すると仮定する。
また具体的な単語などのデータがそれぞれ生成される確率はトピックごとに異なる。
●潜在的意味解析(LSI:Latent Semantic Index、LSA:Latent Semantic Analysis) (赤本)
トピックモデルの手法の1つ。
テキストデータに特異値分解を適用した。
●確率的洗剤意味解析(PLSA:Probabilistic Latent Semantic Analysis)
LSAを確率的に発展させたアルゴリズム。
bag of words (問題集)
文書内での単語の出現回数を値に持つテーブルを各文書ごとに作成し、各文書をベクトルで表現する方法。
TF-IDF (問題集)
トピック分析などで利用される、文書中に含まれる単語の重要度を評価する手法
一般的な単語の重みを低くし、特定の文書に特有な単語を重要視する。
単語の文書内での出現頻度(Term Frequency=TF)、その単語が存在する文書の割合の逆数の対数(Inverse Document Frequency=IDF)の積で定義される。
word2vec (問題集)
単語の分散表現を獲得する、ニューラルネットワークを用いた推論ベースの手法。
●CBOW (問題集)
word2vecのモデルの1つ。
単語周辺の文脈から中心の単語を推定する方法。
●Skip-gram(スキップグラム) (問題集)
word2vecのモデルの1つ。
中心の単語からその文脈を構成する単語を推定する方法。
doc2vec (問題集)
文章の分散表現を獲得する、ニューラルネットワークを用いた推論ベースの手法。
コサイン類似度
2つのベクトル間の類似度の指標で、-1~1の範囲をとる。
分野ごとの研究経過
●機械翻訳や画像説明文生成 ⇒ 大幅な性能向上が見られる。
●構文解析や意味解析 ⇒ 連続的な精度向上は見られるものの基本的な手法は大きく変わらない。
●文脈解析や常識推論 ⇒ 現在のアプローチでは実用的な精度は見込めない。
音声認識
音素 (問題集)
語の意味を区別する音声の最小単位。
ケプストラム (問題集)
音声認識で使われる特徴量の1つ。
音声信号に対してフーリエ変換を行った後、対数を取り、再度フーリエ変換を行い、作成する。
メル尺度 (問題集)
人間の音声知覚の特徴を考慮した尺度。
メル尺度の差が同じとき、人が感じる音高の差が同じになる。
メル周波数ケプストラム係数(MFCC) (問題集)
音声認識で使われる特徴量の1つ。
ケプストラムにメル周波数を考慮したもの。
マルコフ過程 (問題集)
確率モデルの1つ。
マルコフ性(ある時刻の状態がその直前の状態によってのみ決まるという性質)を持つ確率過程(時間とともに変化する確率変数)。
1990年代までの音声認識
隠れマルコフモデル(HMM)による、音自体を判別するための音響モデルと、Nグラム法による語と語のつながりを判別する言語モデルの両方でできている。
音声波形から音素を分類、音素から文字を分類、文字列から単語を予測し、単語から単語列を予測・出力していた。
●隠れマルコフモデル(HMM) (問題集)
確率モデルの1つ。
観測されない隠れた状態をもつマルコフ過程。
混合正規分布モデルに基づく隠れマルコフモデルとして、GMM-HMMがある。
WaveNet (問題集)
2016年にDeepMind社によって開発された音声合成・音声認識に使われるモデル。
PixelCNNというモデルをベースに作られ、畳み込み処理を実施している。
Dilated Causal Convolutionと呼ばれる、層が深くなるほど畳み込み層を離す処理が内部で行われている。
エルマン・ネットワーク
RNN の一種。
音声認識で利用されてきた。
音声認識エージェント
Apple ⇒ Siri
Microsoft ⇒ Cortana
Amazon Echo ⇒ Alexa
Clova WAVE ⇒ Clova
Google Home ⇒ Google Assistant
一般的な音声認識処理における手順
1. 音声波形から周波数や時間変化などの特徴量を抽出する。
2. 音声波形から音素を特定する。
3. どの単語に対応するのかパターンマッチングする。
4. 単語の繋がりを解析し文を生成する。
強化学習
RAINBOW (問題集)
DQNをベースにDueling Network、Double DQN、Noisy Net、Categorical DQNなどのアルゴリズムを全部載せたアルゴリズム。
Actor-Critic (問題集)
行動を選択するActorと、Q関数を計算することで行動を評価するCriticを、交互に学習するアルゴリズム。
Actorは行動を決定し、Criticは環境から情報を集めることで状態の価値を推定し、これに基づいて Actorの行動を評価する。
ロボットの制御などロボット工学でも活用が進んでいる。
Actor-Criticを応用したSoft Actor-Criticという手法がある。
REINFORCE (問題集)
一連の行動による報酬和で方策を評価し、直接方策を改善する方策勾配法系のアルゴリズム。
生成モデル
deepfake (問題集)
GANなどを用いて、人物の画像や映像を合成する技術。
元となる画像または映像を重ね合わせて、非常に自然に合成することが可能。
モード崩壊 (問題集)
GANで起こる問題で、多様性のない画像などを生成してしまう現象のこと。
ディープラーニングの応用に向けて
データセット
MNIST
アメリカの国立標準技術研究所によって提供されている手書き数字のデータベース。
ImageNet
スタンフォード大学がインターネット上から画像を集めて分類したデータセット。
約 1400 万枚の自然画像を有する。
CIFAR
学習用に50,000枚、テスト用に10,000枚用意された10種類もしくは100種類に分類できるデータセット。
Fashion-MNIST
学習用に60,000枚、テスト用に10,000枚用意された10種類に分類できる衣類品画像のデータセット。
ソフトウェアフレームワーク(ソフトウェアライブラリ)
設定ファイルによる記述方法
モデルの定義がテキストで設定でき、簡単に学習を開始させることが出来るというメリットがある。
一方で、ループ構造をもつような RNN など、複雑なモデルを扱う際には、モデルの定義を記述することは難しくなる傾向にある。
●Caffe
●CNTK
プログラムによる記述方法(Pythonライブラリ)
一度書き方を覚えてしまえば、複雑なモデルでも比較的簡単に記述することが出来る。
一方でモデルはそれぞれのフレームワーク固有のソースコードで出来上がるため、モデルが使用しているソフトウェアに依存してしまうという問題がある。
●TensorFlow
Google社提供。
●Keras
TensorFlowのラッパー(TensorFlow上で実行可能な高水準ライブラリ)として機能。
●Chainer
国内企業であるPreferredNetworks社で開発された。
Define-by-Run方式を採用。
●PyTorch
Facebookが開発。
Define-by-Run方式を採用。
2019年にPreferredNetworks社が深層学習フレームワークをChainerからPyTorchへ移行すると発表した。
●seaborn
Pythonでデータを可視化する際に用いられるライブラリ。
使用する際は一般的に「sns」という名称で取り込む。
●scikit-learn
機械学習ライブラリの1つ。
トイデータセットとして「数字の手書き文字データセット」、「アヤメの品種データセット」、「ボストン市の地区別住宅価格データセット」などが入っている。
自動運転
SAEの自動運転レベルの定義概要
●レベル0 自動運転化なし
運転者がすべての運転タスクを実施。
●レベル1 運転支援
システムが前後・左右のいずれかの車両制御に係る。
運転タスクのサブタスクを実施。
●レベル2 部分運転自動化
システムが前後・左右の両方の車両制御に係る。
運転タスクのサブタスクを実施。
●レベル3 条件付運転自動化
システムがすべての運転タスクを実施(限定領域内)。
作業継続が困難な場合の運転者は、システムの介入要求に対して、適切に応答することが期待される。
●レベル4 高度運転自動化
システムがすべての運転タスクを実施(限定領域内)。
作業継続が困難な場合、利用者が応答することは期待されない。
「官民 ITS 構想・ロードマップ 2020」において、自家用車が2025 年までに目指している。
●レベル5 完全自動運転
システムがすべての運転タスクを実施(限定領域内ではない)。
作業継続が困難な場合、利用者が応答することは期待されない。
ドローン
飛行の許可が必要となる空域
●空港等の周辺(進入表面等)の上空の空域
●150m以上の高さの空域
●人口集中地区の上空
承認が必要となる飛行方法
●夜間飛行
●目視外飛行
●30m未満の飛行
●イベント上空飛行
●危険物輸送
●物件投下
各国の取り組み
各国とその国の戦略の組み合わせ
日本 – 新産業構造ビジョン
アメリカ – A Strategy for American Innovation(2015年)
英国 – RAS 2020 戦略
ドイツ – Industrie 4.0(2011年)、デジタル戦略2025
中国 – インターネットプラスAI3年行動実施法案、次世代人工知能発展計画(2017年)
タイ – Thailand 4.0(2015年)
インドネシア – Making Indonesia 4.0(2019年)
EU – Coordinated Plan on Artificial Intelligence(2018年)
2018年時点でのAI関連の論文発行数が多い国
1位:中国
2位:アメリカ
3位:インド
4位:イギリス
5位:ドイツ
6位:日本
主要国際会議
●CVPR
画像認識を主にテーマとしている学会。
●NeurIPS
ニューラルネットワーク技術を主にテーマとしている学会であるが、近年は機械学習をテーマにした発表が増加している。
●ICJI
記号推論などの伝統的なテーマを含む人工知能技術全般をテーマとしている学会。
●AAAI
アメリカで開催されている人工知能分野における国際会議。
AI関連企業数
1位:アメリカ
2位:中国
日本
一般財団法人人工知能学会の9つの指針
1. 人類への貢献
2. 法規制の遵守
3. 他者のプライバシーの尊重
4. 公正性
5.安全性
6. 誠実な振る舞い
7. 社会に対する責任
8. 社会との対話と自己研鑽
9. 人工知能への倫理遵守の要請
経済産業省が定めた先端 IT 人材がどのような人材需給状況にあるかの推定によると、2020年には需給ギャップが広がり人材の不足は4.8万人に及ぶと言われている。
AI戦略2019
内閣府が公表。
「⼈間尊重」、「多様性」 、「持続可能」の3つの理念を掲げている。
高校過程で2022年から「情報Ⅰ」を必修とすることを掲げている。
2025年には、エキスパート人材を年に2,000人育成する目標を掲げている。
人間中心の AI 社会原則
内閣府が公表。
基本概念は下記の3つ。
・人間の尊厳が尊重される社会
・持続性ある社会
・多様な背景を持つ人々が多様な幸せを追求できる社会
データサイエンティストに求められるスキルセット
データサイエンス協会が定義。
●データエンジニアリング力
●データサイエンス力
●ビジネス力
カメラ画像利活用ガイドブック
経済産業省、総務省およびIoT 推進コンソーシアムが、カメラ画像の利活用促進のために2017年に策定。
2018年にはVer2.0を策定した。
2019年5月の道路運送車両法の改正によって、保安基準の対象装置に自動運行装置が追加された。
アメリカ
PREPARING FOR THE FUTURE OF ARTIFICIAL INTELLIGENCE
「AI 実務家や学生に対して倫理観が必要であることを主張している」
THE NATIONAL ARTIFICIAL INTELLIGENCE RESEARCH and DEVELOPMENT STRATEGIC PLAN
「判断結果の理由をユーザーに説明できる AI プログラムを開発することが必要であることを主張した」
ARTIFICIAL INTELLIGENCE AUTOMATION, AND THE ECONOMY
「AI の普及が最大で 300 万件越えの雇用に影響を与える可能性があることを説いている」
ネバダ州では自動運転の走行や運転免許が許可制にて認められた。
2019年時点でのアメリカでの実例
●ピザチェーン店で、自動運転を応用し、ピザの自動配達の実証実験を行っている。
●ファストフード店のドライブスルーにAIを導入し、商品のレコメンデーションを行っている。
●国立研究所で、AIチップ搭載のコンピュータでがん研究を行っている。
中国
BAT
中国の主要IT3社。
Baidu、Alibaba、Tencentの頭文字をとっている。
知的財産
不正競争防止法
2018年にこれを含む法律の一部が改正されたことで、データの利活用を促進するための環境が整備される。主要な措置事項として、ID・パスワードなどにより管理しつつ相手方を限定して提供するデータを不正取得するなどの行為を新たに不正競争行為に位置づけている。
AIが生成した創作物
日本での知的財産制度上の取り扱いとしては、学習済みモデルの利用者に創作意図があり、かつ創作的寄与がある場合において著作物性が認められる。
GDPR(EU一般データ保護規則) (問題集)
「General Data Protection Regulation」の略。
EUを含む欧州経済領域内にいる個人の個人データを保護するためのEUにおける統一ルール。
2018年にEUデータ保護指令(Data Protection Directive95)に代わり施行された。
域内で取得した個人データを域外に移転することを原則禁止している。
EU域内でビジネスを行い、EU域内にいる個人の個人データを取得する日本企業に対しても幅広く適用される。
また、あるサービスが特定のユーザーに関して収集・蓄積した利用履歴などのデータを他のサービスでも再利用できること、すなわち持ち運び可能であるデータポータビリティの権利を認めている。
情報銀行
PDSなどのシステムを活用して個人のデータを管理するとともに、個人の指示又は予め指定した条件に基づき、個人に代わり妥当性を判断の上、データを第三者(他の事業者)に提供する事業及び事業者。
「匿名加工情報」を作成する事業者が行うこと
・個人識別符号の削除
・特定の個人を識別することができる記述等の全部又は一部の削除
・匿名加工情報の加工方法等情報の漏えい防止
その他
バイト単位の小さい順
1. PB(ペタバイト)
2. EB(エクサバイト)
3. ZB(ゼタバイト)
4. YB(ヨタバイト)
Python
IEEE Spectrumが発表した「Top Programming Languages 2019」のランキング1位。
Kaggle (問題集)
データサイエンスのコンペティションプラットフォーム。
MOOCs(Massive Open Online Courses) (問題集)
大規模なオンライン講座群。
●Coursera (問題集)
機械学習などの分野をオンラインで学ぶことが出来る教育プラットフォーム。
スタンフォード大学のアンドリュー・エン(2014年から2017年にかけてBaiduのAI研究所所長を務めた)とダフニー・コラーの2人が設立。
フィルターバブル現象 (問題集)
商品おレコメンドシステムや検索エンジンにおいて、自分が見たいものや欲しい情報にのみ包まれてしまう現象。
インターネット活動家のイーライ・パリサーが2011年に出版した著書名が名前の由来。
XAI(Example AI) (問題集)
解釈性の高いもしくは説明可能なAIのこと。
アメリカのDARPA(国防高等研究計画局)が主導する研究プロジェクトが発端。
●SHAP (問題集)
2016年にLundberg and Leeにより発表された、解釈性の低いモデルを解釈する手法の1つ。
協力ゲーム理論を応用している。
1つのデータにおける予測値の解釈について使えるだけでなく、予測値と変数の関係を見ることもできるなど、ミクロな解釈からマクロな解釈まで網羅的に行える。
Pythonによるパッケージも開発されており、多様なアルゴリズムに活用できることから、実務でも多く活用されている。
●LIME (問題集)
●Anchors (問題集)
●influence (問題集)
人工知能研究の3つの路線
●Google 社・Facebook社路線
言語データによる RNN や映像データからの概念・知識理解を目指す。
●UC Berkeley路線
実世界を対象に研究を進め、知識理解を目指す。
●DeepMind社路線
オンライン空間上でできることをターゲットにして、知識理解を目指す。
共有データセットの整備
下記2つの問題がある。
●著作権の問題
●共有データの作成元に関する問題
これは日本にとっての問題であるが、多くのデータセットが欧米圏で作成されたデータセットであるであることで、日本固有の食べ物を認識しようとすると、それが全く別の国の食べ物としてのみ認識されるという不具合が生じるに至っている。
AIコンピュータ
近年のAIコンピュータでは、従来のノイマン型コンピュータに対し、非ノイマン型コンピュータが注目を浴びている。
具体例として、ニューロコンピュータや量子コンピュータがある。
OpenAI
2015年に設立された人工知能を研究する非営利団体。
イーロン・マスクらアメリカの起業家や投資家などが参加し、2016年にOpenAI Gymの提供をはじめた。
レザバーコンピューティング
レザバーと呼ばれる大自由度力学系が示す多様な時空間パターンを活用したモデルであり、RNNの学習方法の1つとして考案された。
AlphaFold
Alphabet傘下のDeepMindが開発。
AIを使ってタンパク質の構造を見出し新薬開発に活かす。
CASP13コンテストで優勝。
IDCの調査によると、2017年の1年間に生成されたデジタルデータは23ZBであった。
ELSI
「エルシー」と読まれる。
倫理的・法的・社会的課題(Ethical, Legal and Social Issues)の頭文字をとったもの。
OpenCV
当初Intelが開発した画像認識ライブラリ。
2006年に1.0がリリースされ、2015年には3.0がリリースされている。
協調フィルタリング
機械学習を用い、ECサイトなどでユーザの行動履歴から顧客が興味を持ちそうな商品を特定する手法。
PyCharm
JetBrainsが提供している、Pythonに特化した統合開発環境。
ディープブルー
1997年、チェス世界チャンピオンを破ったIBMの開発したチェスAI。
自律型致死兵器システム(LAWS)
2019年に、ジュネーブにおいて、LAWSに関する特定通常兵器使用禁止制限条約(CCW)の政府専門家会合(GGE)が開催され、今後の議論の進め方を含む報告書案がコンセンサスでまとまった。
日本でもLAWS は軍事分野で銃の発明、核兵器の開発に続く第三の革命になるとして「国際人道法や倫理上の観点から到底看過できない」 と政府に対して警鐘を鳴らす学者などの意見が発表されている。
2018年に、KAISTらが、AIを活用した自律型兵器の開発などを推進していると発表している。
Partnership on AI
2016年に、AIの研究や検証、実動におけるベストプラクティスを開発したり共有したりすることを目的とした非営利団体。
Facebook、Amazon、Alphabet(Google)、IBM、Microsoft の5 社によって創設された。
DeepFace
Facebookの研究グループらが2014年に公表したディープラーニングを用いた顔認識システム。
ロボティクスの分野でも、ロボットの動作を覚えさせるために強化学習の活用が進んでおり、各種センサから取得したマルチモーダルな情報に対してディープラーニングを活用する動きが進んでいる。
準委任契約
民間企業でAIを開発する際に用いられる契約の1つ。
特にシステム開発における一部の開発を委託する場合はSES契約という。
OCR技術
印刷された文字や手書きの文字を画像として読み込み、テキストデータ化する技術。
その他
損失関数 + 正則化項 = コスト関数
目的関数 ⊃ コスト関数、誤差関数、損失関数
バッチ学習:データセット内のデータを全て用いて学習する手法。
ミニバッチ学習:いくつかのデータのまとまりをンダムに抽出して逐次的に用いて学習する手法。
オンライン学習:データを1つずつランダムに抽出して逐次的に用いて学習する手法。
ボルツマンマシン
1985年、ジェフリー・ヒントンらによって確率的に動作するニューラルネットワークの一種。
ネットワークの動作に温度の概念を取り入れている。
アフィン変換
機械学習などで用いる画像を拡大・縮小、平行移動、回転、せん断する計算法。
データ拡張
データの水増しをしてデータの不足を補う。
マルチタスク学習
同時に複数の識別問題に対応できるように学習する手法。
DistBelief
2012年に提案された分散並列技術。
Googleが開発した深層分散学習のフレームワーク。
論文も出されていて、深層分散学習の仕組みを理解できる。
醜いアヒルの子定理
認知できる全ての客観的な特徴に基づくと全ての対象は同程度に類似している、つまり特徴を選択しなければ表現の類似度に基づく分類は不可能であることを示している。
次元の呪い
データの次元が増加すると、問題の算法が指数関数的に大きくなること。
確定的モデル
ディープラーニングのモデルの分類の1つ。
例として深層信念ネットワークがある。
確率的モデル
ディープラーニングのモデルの分類の1つ。
例として深層ボルツマンマシン(Boltzmann machine)がある。
Adversarial Examples
学習済みのディープニューラルネットモデルを欺くように人工的に作られたサンプルのこと。
人間では認識しづらいが、AIが認識を誤るような情報を加えている。
より具体的には、サンプルに対して微小な摂動を加えることで、作為的にモデルの誤認識を引き起こすことができる。
人工知能研究の変遷
パターン処理 -> 記号処理 -> 知識の蓄積
画像キャプション
ある画像からそこに写っているものの説明を生成する、画像処理と自然言語処理の融合分野。
キャプションは、対象となる画像をCNNに入力し、そこから得られた特徴をLSTMに入力することで生成することが可能である。
残差
モデルによって出力された値(予測値)と実際の測定値(正解値)の差。
残差を用いて係数パラメータを推定する代表的なアルゴリズムに最小二乗法と最尤推定法がある。
最小二乗法
符号を考えなくてよくなり計算がしやすくなる。
サンプル中に大きく外れた異常値が混じっている場合、この異常値に線が大きく引っ張られるので異常値を考慮する必要がある。
欠損値
全ての欠損値が完全に生じている場合には、下記の手法を使ってこれに対処することができる。
●リストワイズ法
欠損があるサンプルをそのまま削除してしまう。
欠損に偏りがあった場合には、データ全体の傾向を大きく変えてしまうことになるので使用する際には欠損に特定の偏りがないかを確認する必要がある。
●回帰補完
欠損しているある特徴量と相関が強い他の特徴量が存在している場合に利用される方法。
OpenPose
深層学習を用いて人物の姿勢を推定するアルゴリズム。
2017年にカーネギーメロン大学の研究チームらが公表。
エッジコンピューティング
工場などの現場にサーバーを分散配置するような、端末の近くにサーバを分散配置すること。
Colaboratory
Googleが提供する、ブラウザからPythonを記述し実行できるサービス。
P値
統計的優位性を判断する際に用いられる優位確率。
LOD
ウェブ上でコンピュータ処理に適したデータを公開・共有するための方法。
WikipediaをLOD化したDBpediaも作られている。
Define-by-Run
ニューラルの設計を動的に行う。
計算グラフの構築と順伝播処理の実行が同時に行える。
MAML
メタ学習のアルゴリズムの1つ。
回帰、分類、強化学習等のタスクに適用可能である。
最適化処理において、勾配の勾配を求める。
更新後の目的関数の値の和が小さくなるように初期パラメータを決定する。
ニューラル常微分方程式
ResNetの課題であった多くのメモリと時間を要する課題を解決するため、中間層を微分方程式として捉える手法。
NIPS2018のベストペーパーに選ばれた。
MaaS
「ICTを活用してマイカー以外の移動をシームレスにつなぐ」概念。
データバイアス問題
人に代わりデータ駆動型意思決定が行われる場合、学習データに内在する隔たりや偏見が判定に影響すること。
赤池情報量規準
統計モデルの良さを評価するための指標の1つ。
同義用語
・特徴量 ⇒ 説明変数、パラメータ
・ラベル ⇒ 目的変数、正解値、被説明変数
・過学習 ⇒ オーバーフィッティング
人名
スティーブン・ホーキング
「人工知能の進化は人類の終焉を意味する」と発言。
ヤン・ルカン(Yann LeCun)
LeNetの提案者。
Facebook 社が招いたディープラーニングの研究者。

コメント