
前回

の続き。
今回はデータの割り振りと、学習データとテストデータへの分割について。
実装例
# モジュールのインポート
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
from matplotlib.colors import ListedColormap
import sklearn
from sklearn.linear_model import LogisticRegression
from sklearn import metrics
# データセットのインポート
file=pd.read_csv('logistic.csv',header=None)
# データの割り振り
X=file.iloc[:,0:2]
Y=file.iloc[:,2]
# データセットを学習データ(8割)とテストデータ(2割)に分割(random_stateは0)
X_train, X_test, Y_train, Y_test = sklearn.model_selection.train_test_split(X, Y, test_size=0.2, random_state=0)
# 分割の確認
print('分割の確認:',X_train.shape, X_test.shape, Y_train.shape, Y_test.shape)
# 学習実行
# インスタンスの作成
model=LogisticRegression()
# モデルの作成
model.fit(X_train,Y_train)
# 直線の確認
# 切片
print('切片の値 = ', model.intercept_)
# 係数
print('係数の値 = ', model.coef_)
# 学習データからの予測値
pred_train = model.predict(X_train)
# テストデータからの予測値
pred_test = model.predict(X_test)
# 学習データを用いた分類モデルの評価
print('正解率(学習データ) = ', metrics.accuracy_score(Y_train, pred_train))
print('適合率(学習データ) = ', metrics.precision_score(Y_train, pred_train))
print('再現率(学習データ) = ', metrics.recall_score(Y_train, pred_train))
print('F値(学習データ) = ', metrics.f1_score(Y_train, pred_train))
# テストデータを用いた分類モデルの評価
print('正解率(テストデータ) = ', metrics.accuracy_score(Y_test, pred_test))
print('適合率(テストデータ) = ', metrics.precision_score(Y_test, pred_test))
print('再現率(テストデータ) = ', metrics.recall_score(Y_test, pred_test))
print('F値(テストデータ) = ', metrics.f1_score(Y_test, pred_test))
# データセットおよび直線の図示
plt.figure(figsize=(4,4))
plt.scatter(file.iloc[:,0], file.iloc[:,1],c=file.iloc[:,2], cmap=ListedColormap(['#FF0000', '#0000FF']))
plt.plot(file.iloc[:,0], -file.iloc[:,0]*model.coef_[0,0]/model.coef_[0,1]-model.intercept_[0]/model.coef_[0,1])
plt.show()出力例
分割の確認: (160, 2) (40, 2) (160,) (40,)
切片の値 = [-9.71024304]
係数の値 = [[0.04871103 1.89741032]]
正解率(学習データ) = 0.91875
適合率(学習データ) = 0.9195402298850575
再現率(学習データ) = 0.9302325581395349
F値(学習データ) = 0.9248554913294798
正解率(テストデータ) = 0.875
適合率(テストデータ) = 0.8125
再現率(テストデータ) = 0.8666666666666667
F値(テストデータ) = 0.8387096774193549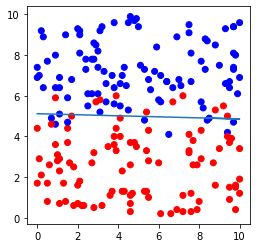
実際にプログラムを実行したい場合は、下記ボタンよりcsvファイル「logistic.csv」をダウンロードしてプログラムの保存先に保存すること。
3. データの割り振り
データセットをインポートしたら、特徴量と分類値(0または1)にデータを分ける。
# データの割り振り
X=file.iloc[:,0:2]
Y=file.iloc[:,2]コード「iloc」の詳細は下記を参照。
実装例のコードを詳しく見ていくと次のようになる。
X=file.iloc[:,0:2]⇒データセット「file」の中の、0列目から1列目までのデータを全て取り出し、そのデータ群を特徴量Xに代入するコード。
「file」にはデータセット「logistic.csv」が格納されており、0列目にはx座標の値、1列目にはy座標の値が入っている。
(座標のパラメータxと特徴量Xは別物なので注意。)
Y=file.iloc[:,2]⇒データセット「file」の中の、2列目のデータを全て取り出し、そのデータ群を分類値Yに代入するコード。
「file」にはデータセット「logistic.csv」が格納されており、2列目には「0」または「1」の値が入っている。
(座標のパラメータyと分類値Yは別物なので注意。)
4. 学習データとテストデータへの分割
続いて、データセットを実際に学習に用いてモデルを作るための学習データと、生成したモデルを評価するためのテストデータに分割する。
# データセットを学習データ(8割)とテストデータ(2割)に分割(random_stateは0)
X_train, X_test, Y_train, Y_test = sklearn.model_selection.train_test_split(X, Y, test_size=0.2, random_state=0)
# 分割の確認
print('分割の確認:',X_train.shape, X_test.shape, Y_train.shape, Y_test.shape)学習データとテストデータについては下記を参照。
実装例のコードを詳しく見ていくと次のようになる。
X_train, X_test, Y_train, Y_test = sklearn.model_selection.train_test_split(X, Y, test_size=0.2, random_state=0)⇒特徴量Xのデータを特徴量の学習データX_trainとテストデータX_testに、分類値Yのデータを分類値の学習データY_trainとテストデータY_testに分割するためのコード。
ただし、学習データとテストデータの比率は8:2であり、計算のたびにデータがランダムに変わらないようにしている。
print('分割の確認:',X_train.shape, X_test.shape, Y_train.shape, Y_test.shape)⇒分割後のデータX_train、X_test、Y_train、Y_testのデータ構造を確認するためのコード。
今回は200個のデータを8:2に分割しているため、出力は下記のようになる。
分割の確認: (160, 2) (40, 2) (160,) (40,)次回予告
次回は、実際にロジスティック回帰を実行するコードを見ていく。
といっても、こちらも回帰分析の実装例と大差ないのですんなり終わると思う。
END
※追記。
ロジスティック回帰の実行コードについて。
コメント